
Understanding Quantization in Machine Learning
What is Quantization?
Quantization is a key method in machine learning used to reduce the size of model data. This allows large language models (LLMs) to run efficiently, even on devices with limited resources.
The Value of Quantization
As LLMs grow in size and complexity, they require more storage and memory. Quantization helps by shrinking the memory footprint of these models, making them suitable for various applications, such as natural language processing and scientific modeling. Post-training quantization (PTQ) compresses model weights efficiently, without needing retraining, facilitating cost-effective deployment.
Challenges of Current LLMs
Many LLMs have high storage needs, making them hard to deploy on limited hardware. Models over 200GB can quickly exceed the capacity of memory bandwidth in high-end GPUs. Traditional methods, like vector quantization (VQ), require large codebooks that take up too much memory, affecting speed and performance.
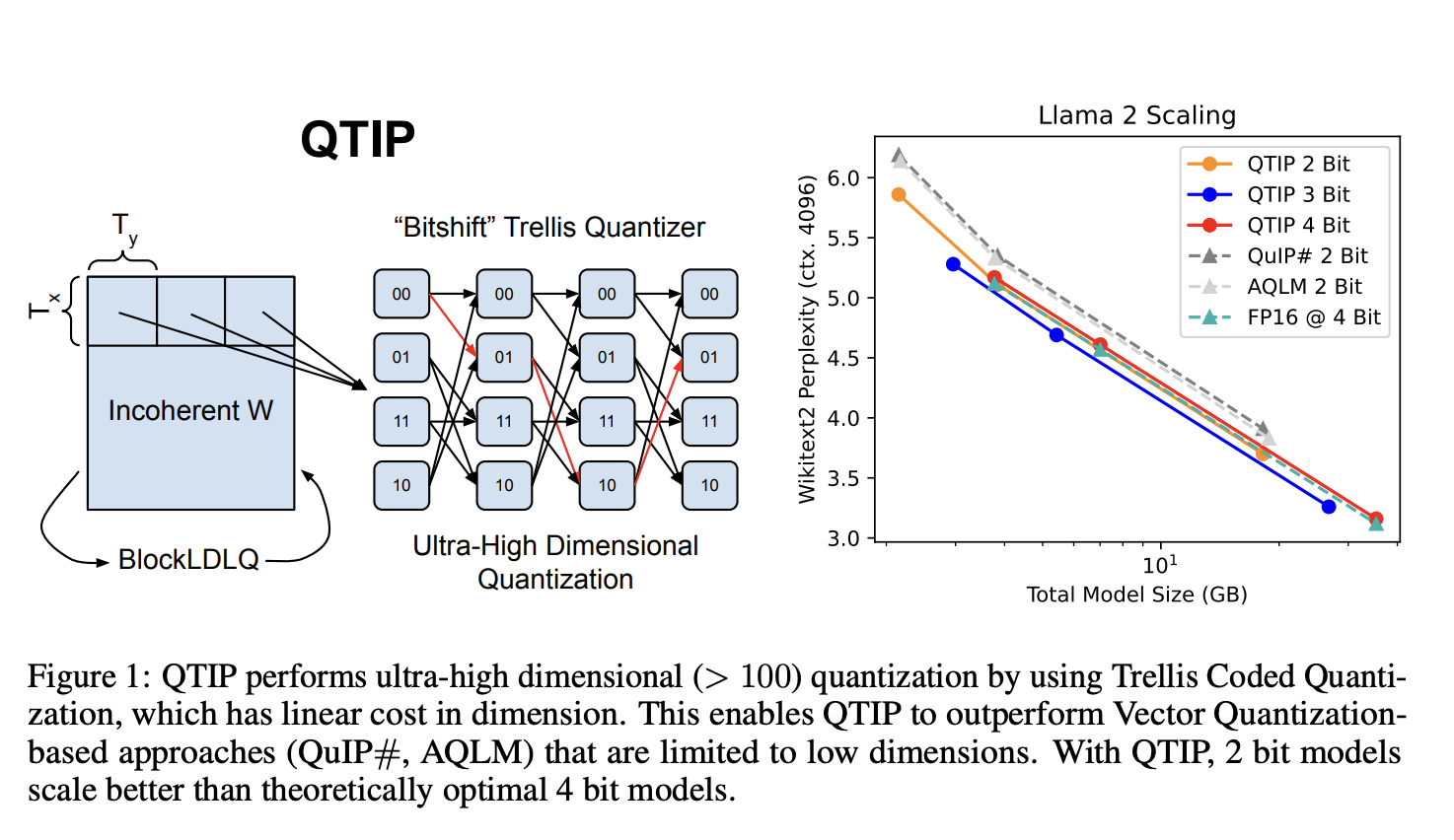
Introducing QTIP: A New Solution
Researchers from Cornell University developed a new method called QTIP, which uses trellis-coded quantization (TCQ) for better efficiency. QTIP allows for high-dimensional data compression without the usual memory issues associated with VQ.
How QTIP Works
QTIP improves over traditional methods by using a special bitshift trellis that reduces the need for large codebooks. This innovative approach generates data efficiently in memory, which also helps in maintaining low storage costs and quick inference times.
Performance Benefits of QTIP
In tests, QTIP demonstrated significant improvements in accuracy and speed compared to existing methods. For instance, when quantizing the Llama 2 model, QTIP achieved better compression quality and faster processing without extra fine-tuning, which is beneficial for real-time applications.
Key Advantages of QTIP
– **Improved Compression Efficiency:** Achieves superior model compression without sacrificing quality.
– **Minimal Memory Requirements:** Reduces memory needs and speeds up processing with simple instructions.
– **Enhanced Adaptability:** Works well on various hardware, including GPUs and ARM CPUs.
– **Higher-Quality Inference:** Outperforms previous methods in accuracy across different model sizes.
– **Ultra-High-Dimensional Quantization:** Successfully handles complex dimensions, improving scalability.
Conclusion
QTIP represents a breakthrough in making large language models more accessible and efficient without compromising accuracy or speed. This method addresses the limitations of traditional quantization techniques, promising better performance across various hardware platforms.
Explore More
Check out the research paper and models available on HuggingFace. Follow us on Twitter, join our Telegram Channel, and connect on LinkedIn. Don’t forget to subscribe to our newsletter for more updates!
Leverage AI for Your Business
Stay competitive by using AI to enhance your operations. Identify automation opportunities, define performance metrics, select suitable AI tools, and implement gradually for best results. For AI management advice, reach out to us at hello@itinai.com. For continuous insights, stay connected on Telegram or Twitter.
Discover how AI can transform your sales processes and customer engagement by exploring our solutions at itinai.com.
























