
Practical AI Solutions for Improving Large Language Model Reasoning
Challenge in Enhancing LLMs’ Reasoning Abilities
Enhancing reasoning abilities of Large Language Models (LLMs) for complex logical and mathematical tasks remains a challenge due to the lack of high-quality preference data for fine-tuning reward models (RMs).
Addressing Data Efficiency with CodePMP
CodePMP is a novel pretraining method that generates preference data from publicly available source code tailored for reasoning tasks, improving efficiency and scalability of RM fine-tuning.
Key Components of CodePMP
CodePMP involves Reward Modeling (RM) and Language Modeling (LM) components, training models on code-preference pairs and chosen responses to enhance reasoning performance.
Significant Improvements in Reasoning Performance
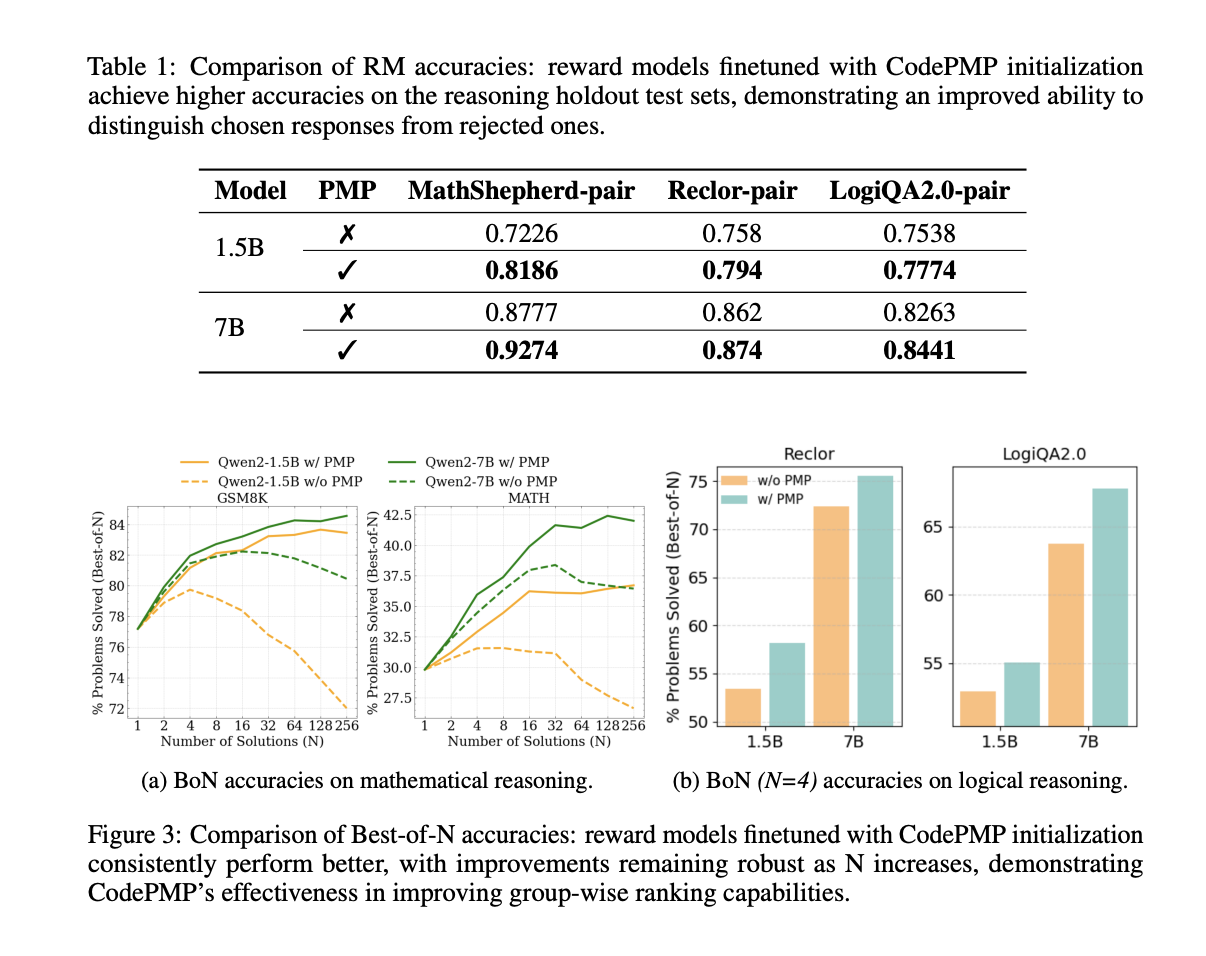
CodePMP demonstrated improved accuracy and performance across mathematical and logical reasoning tasks, providing a cost-effective solution for enhancing LLM capabilities.
Scalable and Efficient Approach
CodePMP offers a scalable and efficient approach to boost reasoning abilities in large language models, showcasing robust improvements across diverse reasoning domains.


























