
Practical Solutions for Multilingual Speech Processing
Introducing XEUS: A Cross-lingual Encoder for Universal Speech
Self-supervised learning (SSL) has expanded the reach of speech technologies to many languages by minimizing the need for labeled data. However, current models only support 100-150 of the world’s 7,000+ languages. This limitation is largely due to the scarcity of transcribed speech, as only about half of these languages have formal writing systems, and even fewer have the resources to generate the extensive annotated data needed for training. While SSL models can operate with unlabeled data, they typically cover a narrow range of languages. Projects like MMS have extended coverage to over 1,000 languages but need help with data noise and a lack of diverse recording conditions.
Researchers from Carnegie Mellon University, Shanghai Jiaotong University, and Toyota Technological Institute in Chicago have developed XEUS, a Cross-lingual Encoder for Universal Speech. XEUS is trained on over 1 million hours of data from 4,057 languages, significantly increasing the language coverage of SSL models. This includes a new corpus of 7,413 hours from 4,057 languages, which will be publicly released. XEUS incorporates a novel dereverberation objective for enhanced robustness. It outperforms state-of-the-art models in various benchmarks, including ML-SUPERB. To support further research, the researchers will release XEUS, its code, training configurations, checkpoints, and training logs.
SSL has advanced speech processing by enabling neural networks to learn from large amounts of unlabeled data, which can then be fine-tuned for various tasks. Multilingual SSL models can leverage cross-lingual transfer learning but only scale to cover a few languages. XEUS, however, scales to 4,057 languages, surpassing models like Meta’s MMS. XEUS includes a novel dereverberation objective during training to handle noisy and diverse speech. Unlike state-of-the-art models that often use closed datasets and lack transparency, XEUS is fully open, with publicly available data, training code, and extensive documentation, facilitating further research into large-scale multilingual SSL.
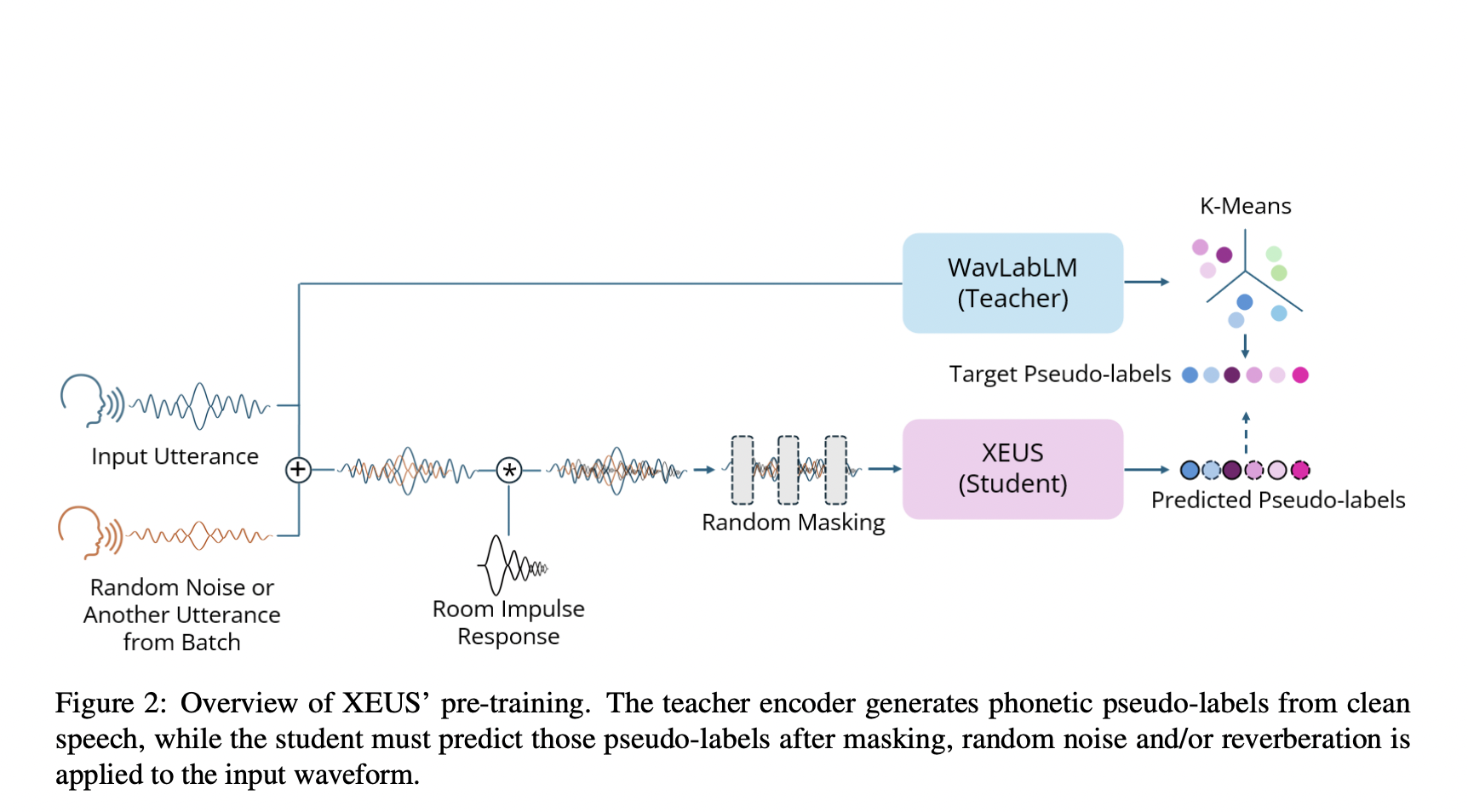
XEUS is pre-trained using a vast dataset of 1.081 million hours across 4,057 languages, compiled from 37 public speech datasets and additional sources like Global Recordings Network, WikiTongues, and Jesus Dramas. Unique data types enhance its robustness, such as accented speech and code-switching. XEUS incorporates new objectives, including dereverberation and noise reduction, during training. The model architecture is based on HuBERT but includes enhancements like E-Branchformer layers and a simplified loss function. The training on 64 NVIDIA A100 GPUs uses advanced augmentation techniques and spans significantly more data than previous models.
The XEUS model is evaluated across various downstream tasks to assess its multilingual and acoustic representation capabilities. It excels in multilingual speech tasks, outperforming state-of-the-art models like XLS-R, MMS, and w2v-BERT on benchmarks such as ML-SUPERB and FLEURS, especially in low-resource language settings. Additionally, XEUS demonstrates strong performance in task universality by matching or exceeding leading models in English-only tasks like emotion recognition and speaker diarization. In acoustic representation, XEUS surpasses models like WavLM and w2v-BERT in generating high-quality speech, which is evident through metrics like MOS and WER.
XEUS is a robust SSL speech encoder trained on over 1 million hours of data spanning 4,057 languages, demonstrating superior performance across a wide range of multilingual and low-resource tasks. XEUS’s dereverberation task enhances its robustness, and despite the limited data for many languages, it still provides valuable results. XEUS advances multilingual research by offering open access to its data and model. However, ethical considerations are crucial, especially in handling speech data from indigenous communities and preventing misuse, such as generating audio deepfakes. XEUS’s integration with accessible platforms aims to democratize speech model development.
AI Solutions for Business Transformation
If you want to evolve your company with AI, stay competitive, and use CMU Researchers’ XEUS for multilingual speech processing. Discover how AI can redefine your way of work and sales processes. Identify automation opportunities, define KPIs, select an AI solution, and implement gradually. For AI KPI management advice, connect with us at hello@itinai.com. For continuous insights into leveraging AI, stay tuned on our Telegram t.me/itinainews or Twitter @itinaicom. Explore solutions at itinai.com.





















