
Advancing MLLMs Through Realistic Chart Understanding Benchmarks
Practical Solutions and Value:
Multimodal large language models (MLLMs) integrate NLP and computer vision, essential for analyzing visual and textual data in scientific papers and financial reports.
Enhancing MLLMs’ ability to comprehend and interpret complex charts is crucial, but current benchmarks often lack diverse and realistic datasets, overestimating MLLM capabilities.
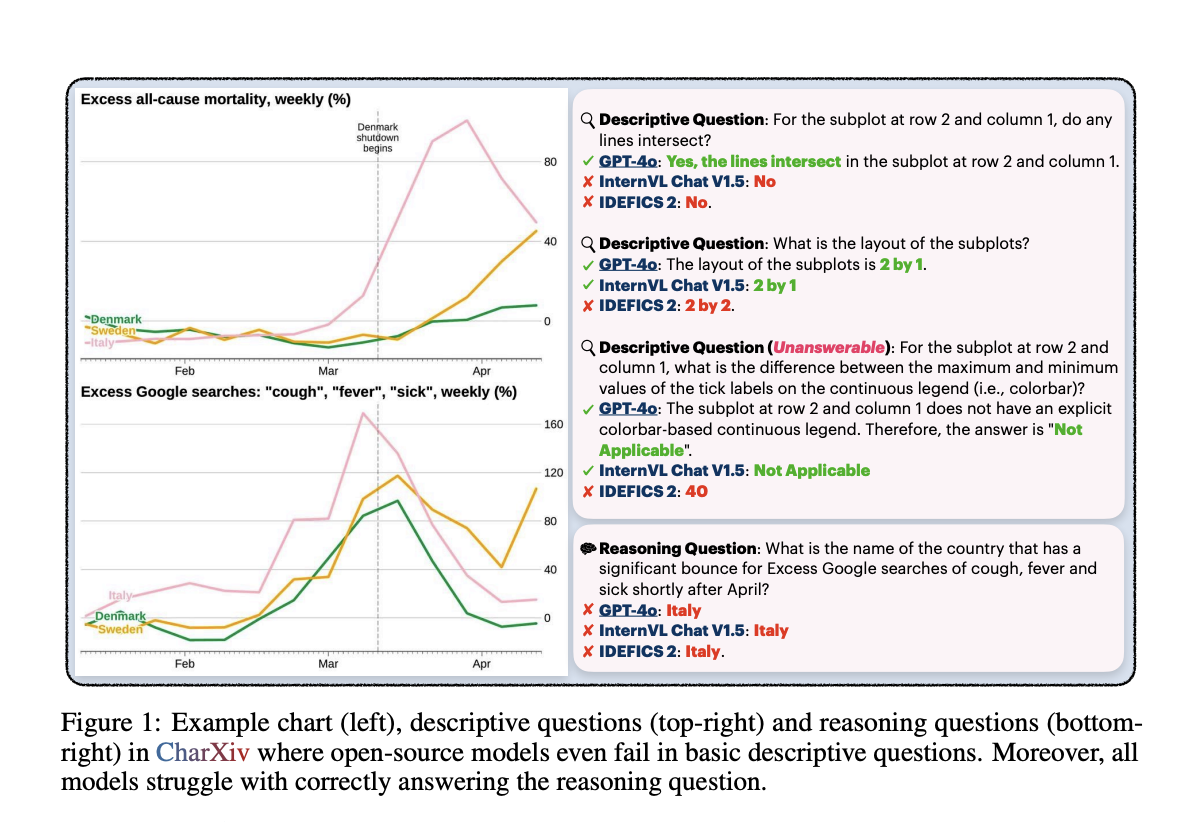
CharXiv, a new evaluation suite, offers 2,323 diverse and complex charts paired with detailed questions to bridge the gap between existing benchmarks and real-world applications.
CharXiv’s meticulous curation process aims to provide a more accurate evaluation environment for MLLMs, leading to improved model performance and reliability in practical applications.
Researchers found a substantial performance gap between open-source and proprietary models, highlighting the need for more robust benchmarks like CharXiv to drive advancements in the field.
CharXiv’s comprehensive approach aims to drive future advancements in MLLM capabilities, ultimately leading to more reliable and effective models for practical applications.
If you want to evolve your company with AI, stay competitive, and use CharXiv for realistic chart understanding benchmarks.
For AI KPI management advice, connect with us at hello@itinai.com. And for continuous insights into leveraging AI, stay tuned on our Telegram or Twitter .


























