
Transforming Natural Language Processing with AI
Introduction to Large Language Models (LLMs)
Large language models (LLMs) are essential tools in various fields like healthcare, education, and technology. They can perform tasks such as language translation, sentiment analysis, and code generation. However, their growth has led to challenges in computation, particularly in memory and energy usage.
Challenges in Inference Clusters
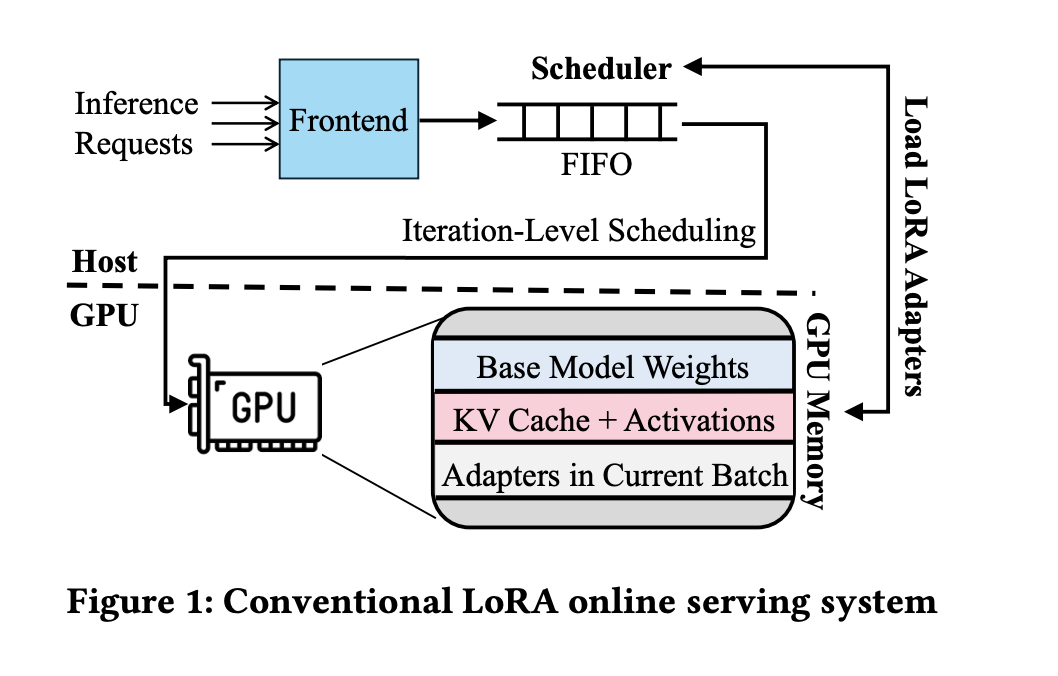
Inference clusters for LLMs face issues like high latency and inefficient memory use. Techniques like Low-Rank Adaptation (LoRA) help reduce memory needs but can slow down performance due to increased memory bandwidth demands. This makes it difficult for systems to handle many requests efficiently.
Current Solutions and Their Limitations
Some existing methods, like S-LoRA, try to improve performance but often fall short under heavy loads. Scheduling methods such as FIFO and SJF can lead to delays and unfulfilled service objectives, particularly when requests vary in size.
Introducing Chameleon: A New Solution
Researchers from the University of Illinois Urbana-Champaign and IBM Research have developed Chameleon, a system designed to enhance LLM inference. Chameleon uses adaptive caching and smart scheduling to improve efficiency.
Key Features of Chameleon
– **Adaptive Caching:** It effectively uses GPU memory to store frequently used adapters, reducing loading times.
– **Dynamic Scheduling:** A multi-level queue prioritizes tasks based on their needs, ensuring fair resource allocation and preventing delays.
Performance Improvements
Chameleon has shown impressive results:
– **Latency Reduction:** Achieved an 80.7% decrease in P99 time-to-first-token (TTFT) latency and a 48.1% drop in P50 TTFT latency.
– **Increased Throughput:** Improved throughput by 1.5 times, allowing more requests to be processed simultaneously.
Scalability and Broader Implications
Chameleon supports adapter ranks from 8 to 128, making it suitable for various tasks. This research paves the way for designing more efficient inference systems for large-scale LLMs.
Conclusion
Chameleon represents a significant advancement in LLM inference, optimizing memory use and task scheduling. This leads to better performance and efficiency in handling diverse requests.
Get Involved
Explore the full research paper and stay updated by following us on Twitter, joining our Telegram Channel, and LinkedIn Group. Join our 55k+ ML SubReddit for more insights.
Leverage AI for Your Business
Evolve your company with AI by:
– **Identifying Automation Opportunities:** Find key interactions that can benefit from AI.
– **Defining KPIs:** Ensure measurable impacts on business outcomes.
– **Selecting AI Solutions:** Choose tools that fit your needs.
– **Implementing Gradually:** Start small, gather data, and expand wisely.
For AI KPI management advice, contact us at hello@itinai.com. Stay tuned for continuous insights on leveraging AI through our Telegram and Twitter channels.























