
The World’s Fastest AI Inference Solution
Unmatched Speed and Efficiency
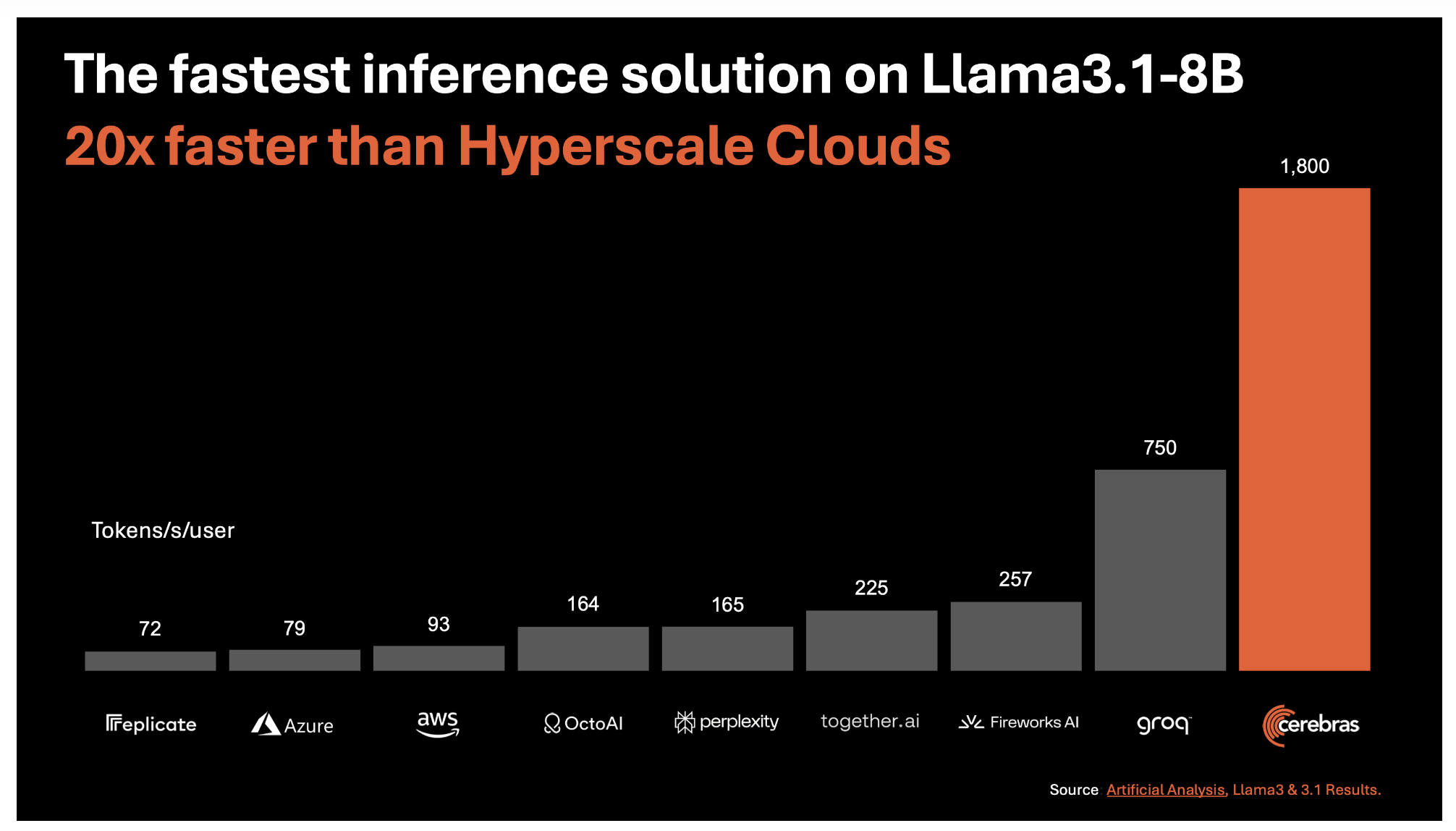
Cerebras Systems introduces Cerebras Inference, delivering unprecedented speed and efficiency for processing large language models. Powered by the third-generation Wafer Scale Engine (WSE-3), it achieves remarkable speeds, approximately 20 times faster than traditional GPU-based solutions, at a fraction of the cost.
Addressing the Memory Bandwidth Challenge
Cerebras has overcome the need for vast memory bandwidth by integrating a massive 44GB of SRAM onto the WSE-3 chip, providing an astounding 21 petabytes per second of aggregate memory bandwidth, 7,000 times greater than the Nvidia H100 GPU. This breakthrough allows Cerebras Inference to easily handle large models, providing faster and more accurate inference.
Maintaining Accuracy with 16-bit Precision
Cerebras retains the original 16-bit precision throughout the inference process, ensuring model outputs are as accurate as possible. Their 16-bit models score up to 5% higher in accuracy than their 8-bit counterparts, making them a superior choice for developers who need both speed and reliability.
Strategic Partnerships and Future Expansion
Cerebras has partnered with leading companies in the AI industry and plans to expand its support for even larger models, solidifying Cerebras Inference as the go-to solution for cutting-edge AI applications. It also offers its inference service across three tiers: Free, Developer, and Enterprise, catering to various users from individual developers to large enterprises.
The Impact on AI Applications
Cerebras Inference’s high-speed performance enables more complex AI workflows and enhances real-time intelligence in large language models. This can revolutionize industries by allowing faster and more accurate decision-making processes, from healthcare to finance, potentially saving lives and enabling quicker and more informed decisions.
Conclusion
Cerebras Inference represents a significant leap forward in AI technology, redefining what is possible in AI by combining unparalleled speed, efficiency, and accuracy. It plays a crucial role in shaping the future of technology, enabling real-time responses in complex AI applications and supporting the development of next-generation AI models.

























