
Practical Solutions for Optimizing Large Language Models
Efficient Optimization Challenges
Training large language models (LLMs) can be costly and time-consuming. As models get bigger, the need for more efficient optimizers grows to reduce training time and resources.
Current Optimization Methods
Existing methods like Adam and Shampoo have their strengths and weaknesses. Adam is computationally efficient but slow in large-batch scenarios. Shampoo offers superior performance but is complex and not scalable for real-time applications.
The Innovation: SOAP
SOAP (ShampoO with Adam in the Preconditioner’s eigenbasis) combines Adam and Shampoo’s strengths. By running Adam on Shampoo’s eigenbasis, SOAP reduces computational overhead and hyperparameters, improving efficiency without compromising accuracy.
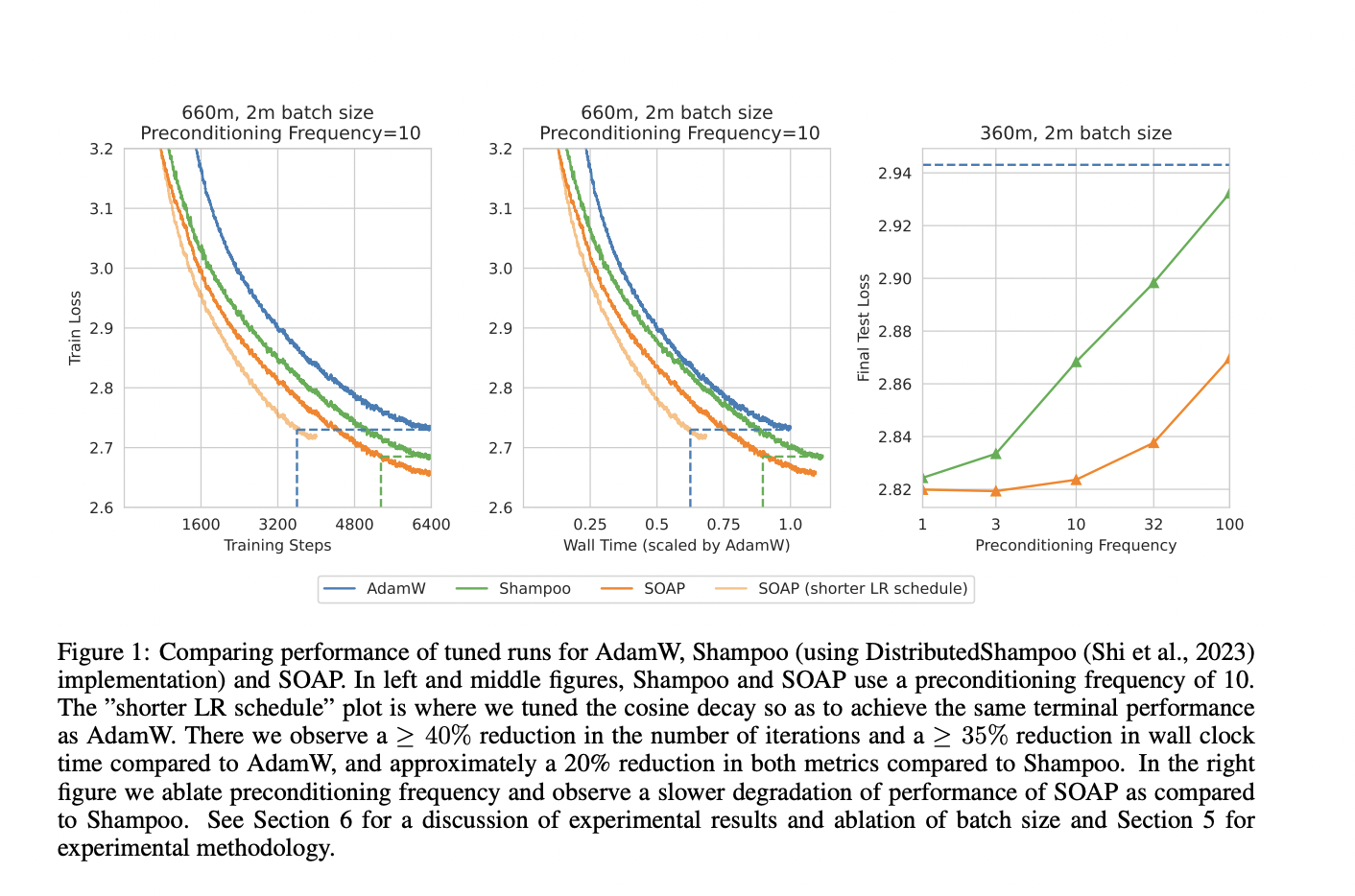
Performance and Efficiency Gains
SOAP reduces training iterations by 40% and wall-clock time by 35% compared to AdamW. It outperforms Shampoo by 20% in both metrics, showcasing its ability to balance efficiency and performance in large-scale deep learning tasks.
Advantages of SOAP
SOAP offers a scalable and efficient solution for training large models, maintaining or exceeding the performance of existing optimizers while reducing computational complexity. It represents a practical standard for optimizing AI models effectively.

























