
<>
Practical Solutions and Value of CALM in Reinforcement Learning
Overview:
Reinforcement Learning (RL) is crucial in Machine Learning for agents to learn from interactions in an environment by receiving rewards. A challenge is assigning credit when feedback is delayed or sparse.
Challenges Addressed:
– Difficulty in determining which actions led to desired outcomes.
– Agents starting without prior knowledge of environment.
– Struggle in complex environments where only final actions produce rewards.
Traditional Approaches:
– Reward shaping and hierarchical reinforcement learning used, requiring domain knowledge and human input.
– Limited scalability due to human intervention.
Introduction of CALM:
– Leverages Large Language Models (LLMs) to automate credit assignment without human-designed rewards.
– Breaks tasks into subgoals for effective agent training.
– Reduces human involvement, making RL systems more scalable.
Key Benefits:
– Automated credit assignment.
– Efficient handling of zero-shot settings.
– Recognition of subgoals without prior examples.
– Improved learning in sparse-reward environments.
Research Findings:
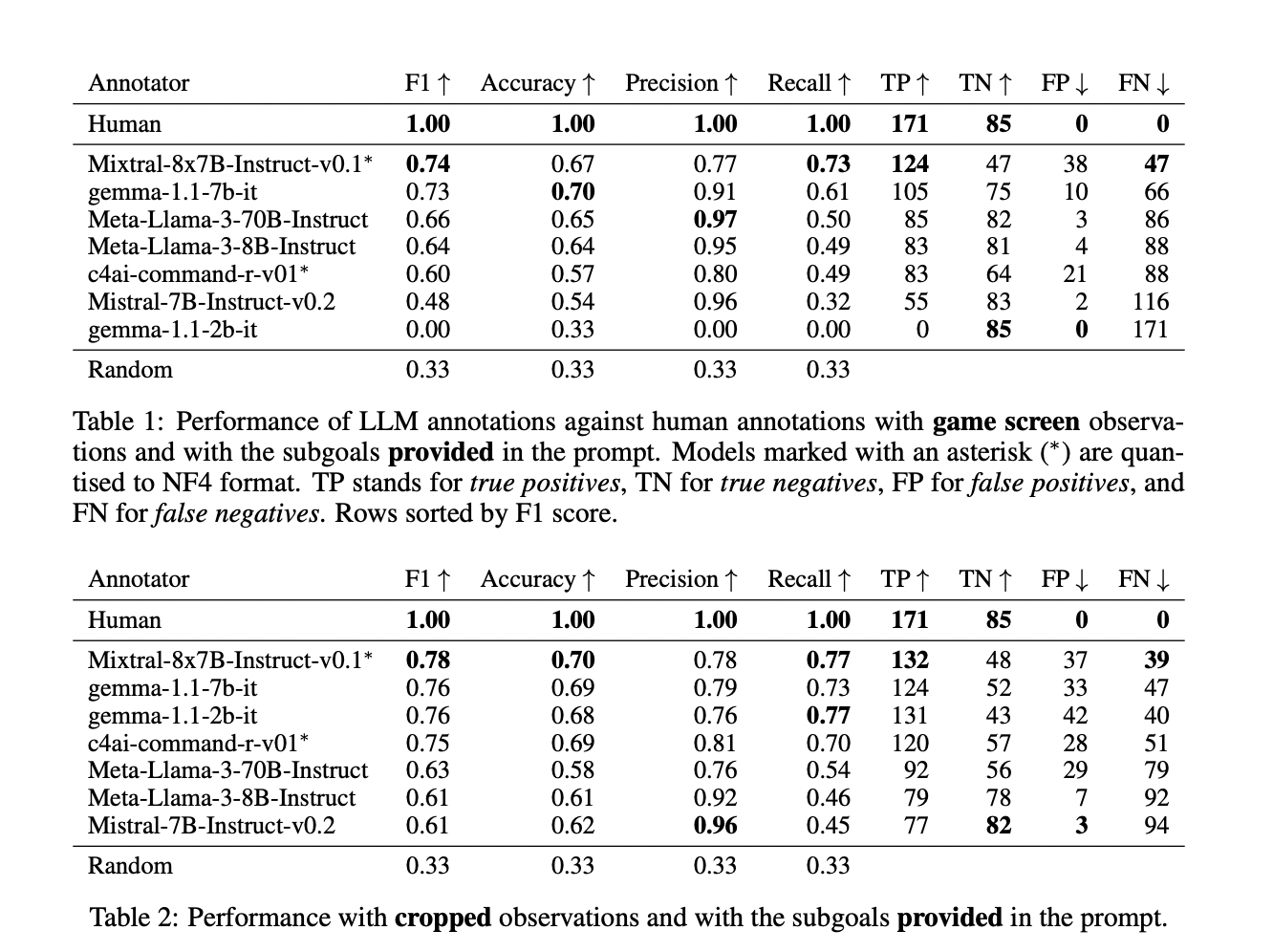
– Successful credit assignment by LLMs in zero-shot settings.
– High accuracy in recognizing subgoals.
– Competitive performance with human annotators.
– Enhances RL performance in various applications.
Conclusion:
CALM effectively addresses credit assignment in RL by leveraging LLMs, reducing human involvement, and improving learning efficiency in sparse-reward environments.
AI Integration Advice:
– Identify automation opportunities for AI in customer interactions.
– Define measurable impact KPIs for AI initiatives.
– Select AI solutions aligned with your needs.
– Implement AI gradually, starting with pilots and expanding usage judiciously.
Get in Touch:
For AI-driven KPI management advice, contact us at hello@itinai.com. For continuous insights, follow us on Telegram or Twitter.



























