
Challenges in Current AI Animation Models
Current AI models for human animation face several issues, including:
- Motion Realism: Many struggle to create realistic and fluid body movements.
- Adaptability: Existing models often rely on limited training datasets, making them less flexible.
- Facial vs. Full-Body Animation: While facial animation has improved, full-body animation remains inconsistent.
- Aspect Ratio Constraints: Many frameworks are limited to specific body proportions and media formats.
A more flexible and scalable approach to motion learning is essential to overcome these challenges.
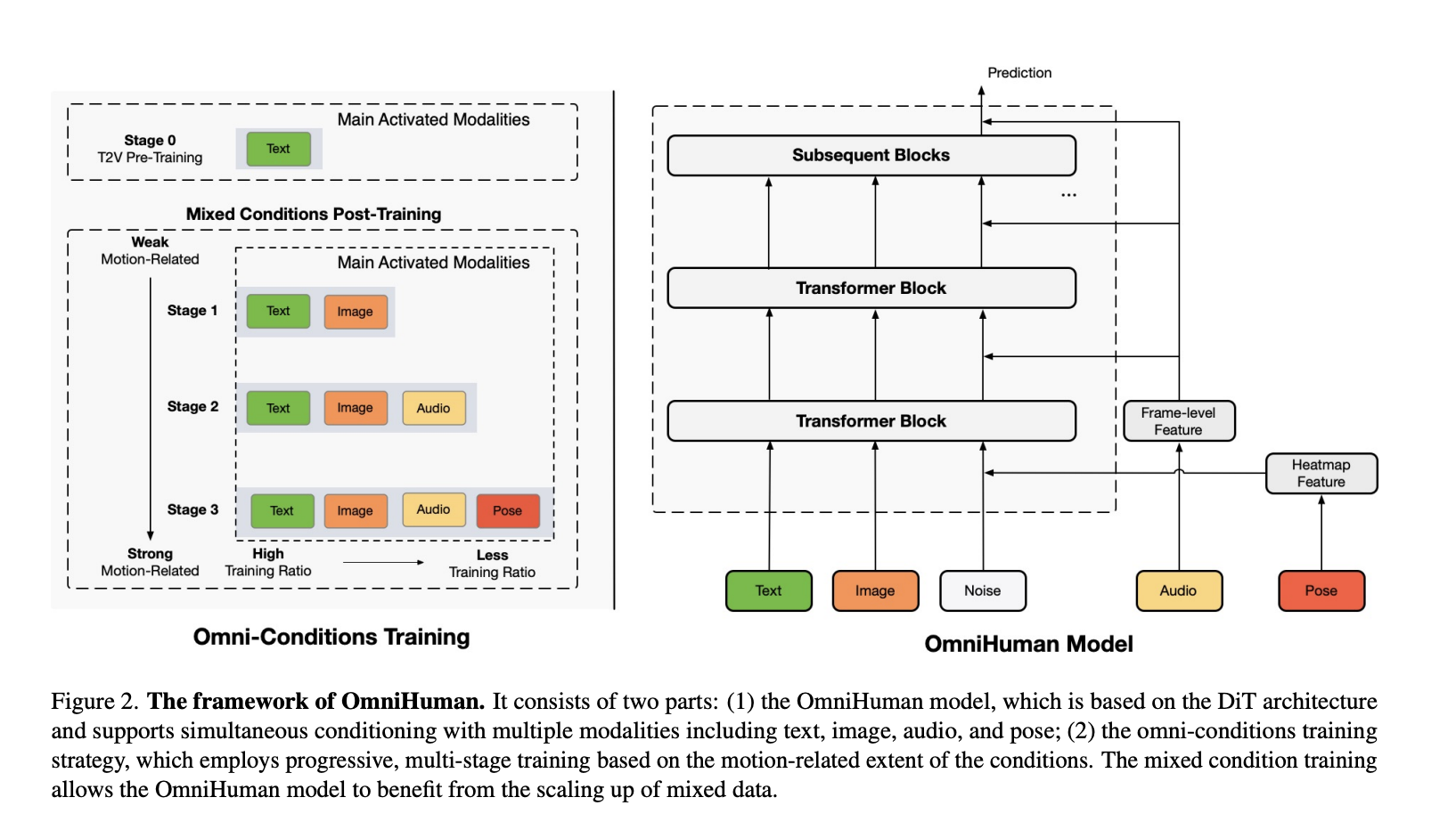
Introducing OmniHuman-1
ByteDance has launched OmniHuman-1, an advanced AI model that creates realistic human videos from a single image and various motion signals, such as audio or video.
Unlike previous models, OmniHuman-1 uses omni-conditions training to enhance motion data scaling and improve gesture realism and body movement.
Key Features of OmniHuman-1
- Audio-Driven Animation: Creates synchronized lip movements and gestures from spoken input.
- Video-Driven Animation: Mimics motion from a reference video.
- Multimodal Fusion: Combines audio and video for precise control over body movements.
Its versatility allows it to adapt to different aspect ratios and body types, making it suitable for a wide range of applications.
Technical Advantages
OmniHuman-1 is built on a Diffusion Transformer (DiT) architecture, offering several key innovations:
- Multimodal Motion Conditioning: Incorporates various conditions during training for better generalization across animation styles.
- Scalable Training Strategy: Optimizes the use of both strong and weak motion conditions for high-quality animation.
- Realistic Motion Generation: Excels in creating natural gestures and interactions, ideal for virtual avatars and digital storytelling.
- Versatile Style Adaptation: Supports various animation styles, including cartoon and stylized outputs.
Performance Highlights
OmniHuman-1 outperforms other models in key areas:
- Lip-sync Accuracy: 5.255 (compared to competitors)
- Fréchet Video Distance (FVD): 15.906 (lower is better)
- Gesture Expressiveness: 47.561 (higher is better)
- Hand Keypoint Confidence: 0.898 (higher is better)
Its ability to generalize across body proportions gives it a competitive edge.
Conclusion
OmniHuman-1 marks a major advancement in AI human animation. By effectively transforming static images into dynamic videos, it serves as a valuable resource for virtual influencers, game development, and AI filmmaking.
As AI-generated content evolves, OmniHuman-1 paves the way for more flexible and adaptable animation solutions, addressing long-standing challenges in motion realism.
Get Involved
Explore the Paper and Project Page. Follow us on Twitter, join our Telegram Channel, and connect on our LinkedIn Group. Join our community of over 75k on our ML SubReddit.
Elevate Your Business with AI
Stay competitive by leveraging OmniHuman-1 for your company’s advantage. Discover how AI can transform your operations:
- Identify Automation Opportunities: Find key areas for AI integration.
- Define KPIs: Measure the impact of AI on your business goals.
- Select an AI Solution: Choose tools that fit your needs.
- Implement Gradually: Start small, gather insights, and expand.
For AI KPI management advice, contact us at hello@itinai.com. Follow us for continuous insights on Telegram or @itinaicom.

























