
Understanding Code Intelligence and Its Growth
Code intelligence is advancing quickly, thanks to improvements in large language models (LLMs). These models help automate programming tasks like code generation, debugging, and testing. They support various languages and fields, making them essential for software development, data science, and solving complex problems. The rise of LLMs is changing how we tackle programming challenges.
Need for Better Benchmarks
There is a significant need for better benchmarks that reflect real-world programming needs. Current datasets, such as HumanEval and MBPP, focus too narrowly on specific areas, missing the broader scope required for full-stack programming. This gap limits our ability to measure and improve LLM performance effectively.
Introducing FullStack Bench and SandboxFusion
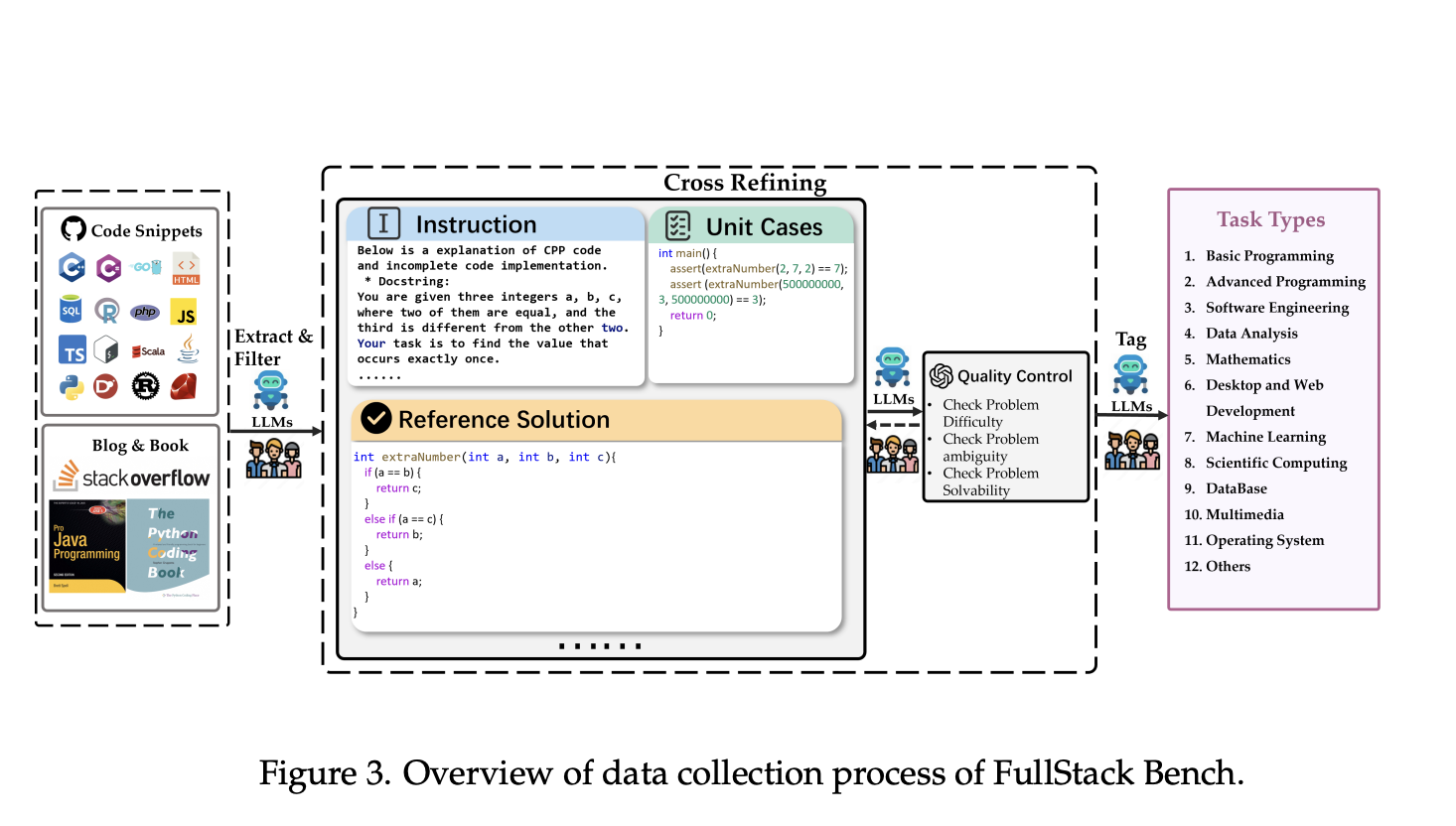
Researchers from ByteDance Seed and M-A-P have developed FullStack Bench, a benchmark that tests LLMs across 11 application domains and supports 16 programming languages. This benchmark includes areas like data analysis, web development, and machine learning.
Features of FullStack Bench
- Contains 3,374 problems with unit tests and varying difficulty levels.
- Problems are designed with human expertise and LLM assistance for quality and diversity.
SandboxFusion: A Unified Execution Environment
SandboxFusion automates code execution and evaluation across multiple languages, supporting 23 programming languages. This tool provides a secure environment for testing LLMs and can work with datasets beyond FullStack Bench.
Performance Evaluation and Findings
Extensive tests showed different performance levels of LLMs across various domains and languages. Some models excelled in basic programming, while others struggled with multimedia tasks. The main evaluation metric, Pass@1, highlighted these challenges.
Scaling Laws and Performance Insights
Researchers found that increasing model size generally improves performance, but some models performed worse at higher scales. For instance, the Qwen2.5-Coder series peaked at 14B parameters but declined at 32B and 72B. This indicates the need for a balance between model size and efficiency.
Significance of FullStack Bench and SandboxFusion
Together, FullStack Bench and SandboxFusion mark important progress in evaluating LLMs. They address existing benchmark limitations, allowing for a more thorough assessment of LLM capabilities across various domains and programming languages. This research sets the stage for future advancements in code intelligence.
Get Involved
Explore the Paper, FullStack Bench, and SandboxFusion. Follow us on Twitter, join our Telegram Channel, and connect with our LinkedIn Group. If you enjoy our work, subscribe to our newsletter and join our 60k+ ML SubReddit.
Transform Your Business with AI
Stay competitive by leveraging AI solutions like FullStack Bench and SandboxFusion. Here’s how AI can enhance your operations:
- Identify Automation Opportunities: Find key areas in customer interactions that can benefit from AI.
- Define KPIs: Ensure your AI initiatives have measurable impacts.
- Select an AI Solution: Choose tools that meet your needs and allow for customization.
- Implement Gradually: Start small, collect data, and expand AI usage wisely.
For advice on AI KPI management, contact us at hello@itinai.com. For ongoing insights into AI, follow us on Telegram or Twitter.
Discover how AI can transform your sales processes and customer engagement at itinai.com.
























