Introduction
Monitoring and extracting trends from web content has become essential for market research, content creation, and staying competitive. This guide outlines a practical approach to building a trend-finding tool using Python without relying on external APIs or complex setups.
Web Scraping
We begin by scraping publicly accessible websites to gather textual data. The following code snippet demonstrates how to fetch content from specified URLs, extract paragraphs, and prepare the text for analysis:
import requests
from bs4 import BeautifulSoup
urls = ["https://en.wikipedia.org/wiki/Natural_language_processing",
"https://en.wikipedia.org/wiki/Machine_learning"]
collected_texts = []
for url in urls:
response = requests.get(url, headers={"User-Agent": "Mozilla/5.0"})
if response.status_code == 200:
soup = BeautifulSoup(response.text, 'html.parser')
paragraphs = [p.get_text() for p in soup.find_all('p')]
page_text = " ".join(paragraphs)
collected_texts.append(page_text.strip())
else:
print(f"Failed to retrieve {url}")
Data Cleaning
Next, we clean the scraped text to ensure it is suitable for analysis. This involves converting text to lowercase, removing punctuation, and filtering out common stopwords:
import re
import nltk
nltk.download('stopwords')
from nltk.corpus import stopwords
stop_words = set(stopwords.words('english'))
cleaned_texts = []
for text in collected_texts:
text = re.sub(r'[^A-Za-zs]', ' ', text).lower()
words = [w for w in text.split() if w not in stop_words]
cleaned_texts.append(" ".join(words))
Keyword Analysis
We then analyze the frequency of words in the cleaned text to identify the top 10 keywords, which helps in understanding dominant trends:
from collections import Counter
all_text = " ".join(cleaned_texts)
word_counts = Counter(all_text.split())
common_words = word_counts.most_common(10)
print("Top 10 keywords:", common_words)
Sentiment Analysis
We perform sentiment analysis on each document to evaluate the emotional tone using TextBlob. This provides insights into the overall mood of the text:
!pip install textblob
from textblob import TextBlob
for i, text in enumerate(cleaned_texts, 1):
polarity = TextBlob(text).sentiment.polarity
if polarity > 0.1:
sentiment = "Positive"
Topic Modeling
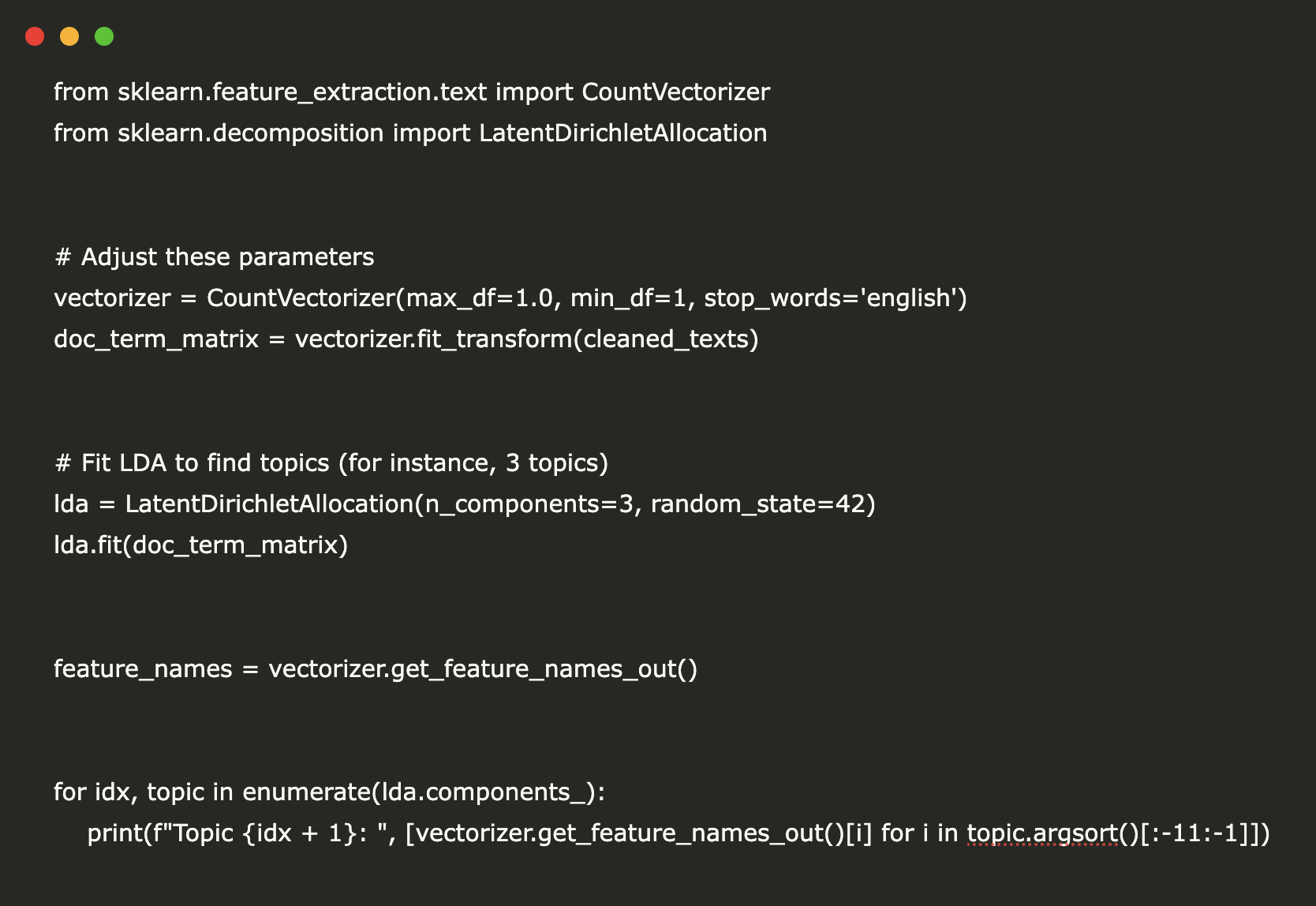
Using Latent Dirichlet Allocation (LDA), we identify underlying topics within the text corpus. This helps summarize key concepts:
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.decomposition import LatentDirichletAllocation
vectorizer = CountVectorizer(max_df=1.0, min_df=1, stop_words='english')
doc_term_matrix = vectorizer.fit_transform(cleaned_texts)
lda = LatentDirichletAllocation(n_components=3, random_state=42)
lda.fit(doc_term_matrix)
feature_names = vectorizer.get_feature_names_out()
for idx, topic in enumerate(lda.components_):
print(f"Topic {idx + 1}: ", [vectorizer.get_feature_names_out()[i] for i in topic.argsort()[:-11:-1]])
Word Cloud Visualization
Finally, we visualize the prominent keywords using a word cloud, which allows for intuitive exploration of the main trends:
from wordcloud import WordCloud
import matplotlib.pyplot as plt
combined_text = " ".join(cleaned_texts)
wordcloud = WordCloud(width=800, height=400, background_color='white', colormap='viridis').generate(combined_text)
plt.figure(figsize=(10, 6))
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis('off')
plt.title("Word Cloud of Scraped Text", fontsize=16)
plt.show()
Conclusion
In conclusion, we have built a robust trend-finding tool that enables continuous tracking of industry trends and insights from web content. This straightforward approach allows businesses to make informed decisions based on real-time data.
Next Steps
Explore how artificial intelligence can transform your business processes. Identify key performance indicators (KPIs) to measure the impact of AI investments, select suitable tools, and start with small projects to gradually expand your AI initiatives.
Contact Us
If you need assistance with managing AI in your business, reach out to us at hello@itinai.ru. Connect with us on Telegram, X, and LinkedIn.



























