
Revolutionizing Language Models with LLaDA
The world of large language models has typically relied on autoregressive methods, which predict text one word at a time from left to right. While effective, these methods have limitations in speed and reasoning. A research team from China has introduced a new approach called LLaDA, which uses a diffusion-based architecture to enhance how language models understand and generate text.
Challenges with Current Language Models
Current models predict the next word, which becomes more complex as the context increases. This sequential method slows down processing and struggles with tasks that require reverse reasoning. For example:
- Forward Task: Given “Roses are red,” models can easily continue with “violets are blue.”
- Reversal Task: Given “violets are blue,” models often fail to recall “Roses are red.”
This limitation arises because they are trained to predict text only from left to right. Although masked language models like BERT exist, they have fixed masking ratios that restrict their generative abilities.
Introducing LLaDA
LLaDA (Large Language Diffusion with mAsking) uses a dynamic masking strategy to overcome these limitations. Unlike traditional models, LLaDA processes words in parallel, allowing it to learn relationships in all directions at once.
How LLaDA Works
LLaDA’s architecture includes a transformer without causal masking and is trained in two phases:
- Pre-training: The model learns to fill in randomly masked text segments from a vast dataset. For example, it can predict missing words in a sentence like “[MASK] are red, [MASK] are blue.”
- Supervised Fine-Tuning: The model adapts to specific tasks by masking only the response part, enhancing its understanding while maintaining flexibility.
During text generation, LLaDA starts with fully masked outputs and refines predictions iteratively. It uses a process called “semantic annealing,” where low-confidence predictions are re-evaluated until coherent text is formed.
Performance and Advantages
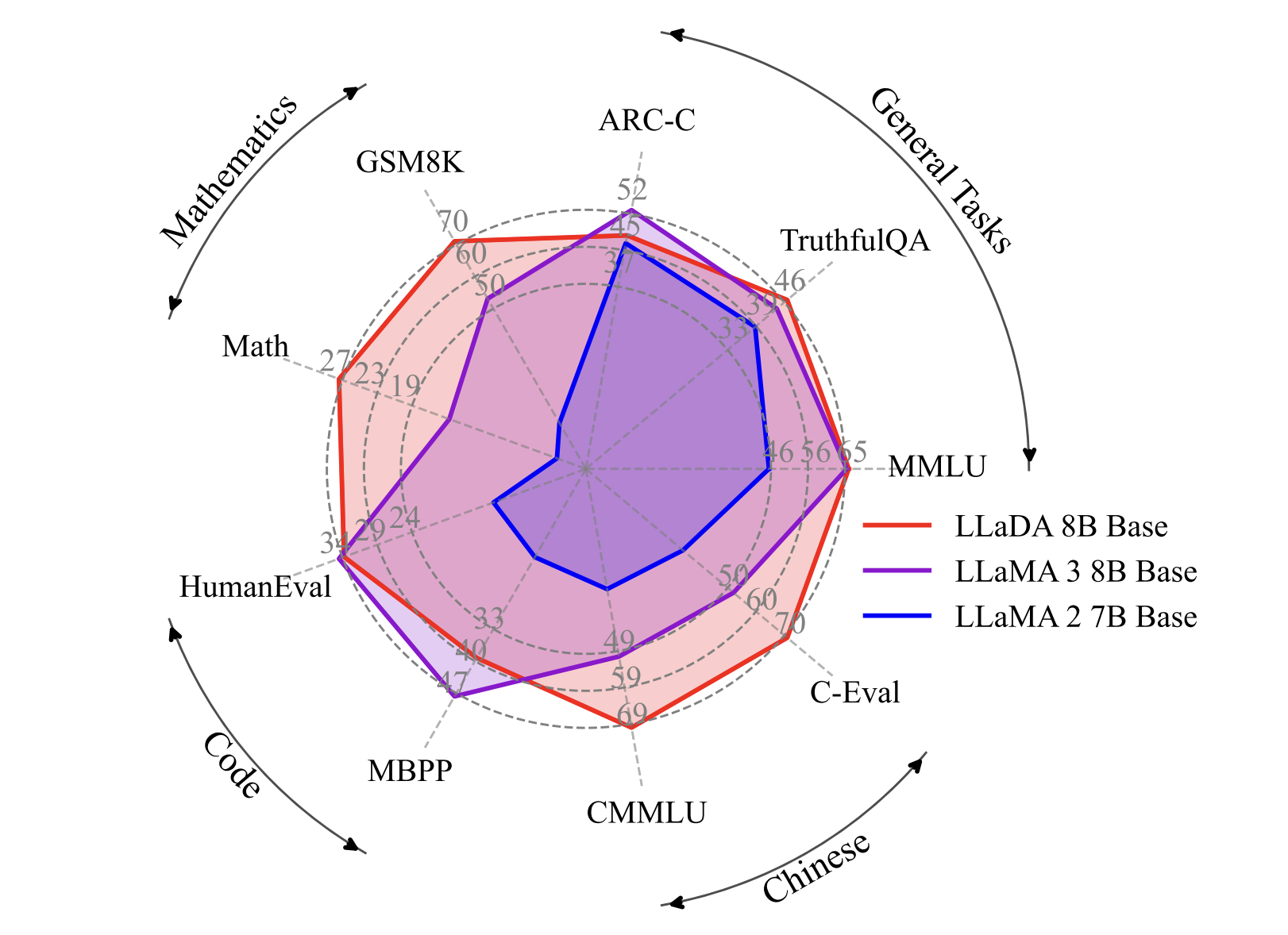
When tested with 8 billion parameters, LLaDA performs as well or better than similar autoregressive models across various benchmarks. Notably, it excels in:
- Backward poem completion: Achieving 42% accuracy compared to GPT-4’s 32%.
- Reversal question-answering tasks: Where traditional models often struggle.
LLaDA also scales efficiently, with computational costs comparable to traditional models, and shows strong performance in tasks like MMLU and GSM8K.
Conclusion
This breakthrough suggests that advanced language capabilities can emerge from innovative generative principles, not just autoregressive methods. While there are still challenges to address, LLaDA paves the way for parallel generation and improved reasoning in language processing.
For businesses looking to leverage AI, consider the following steps:
- Identify Automation Opportunities: Find key customer interactions that can benefit from AI.
- Define KPIs: Ensure measurable impacts on business outcomes.
- Select an AI Solution: Choose tools that fit your needs and allow for customization.
- Implement Gradually: Start with a pilot project, gather data, and expand wisely.
For AI KPI management advice, connect with us at hello@itinai.com. For ongoing insights, follow us on Telegram or @itinaicom.
Discover how AI can transform your sales processes and customer engagement at itinai.com.






















