
Block Transformer: Enhancing Inference Efficiency in Large Language Models
Practical Solutions and Value Highlights:
– Large language models face computational challenges due to self-attention mechanism.
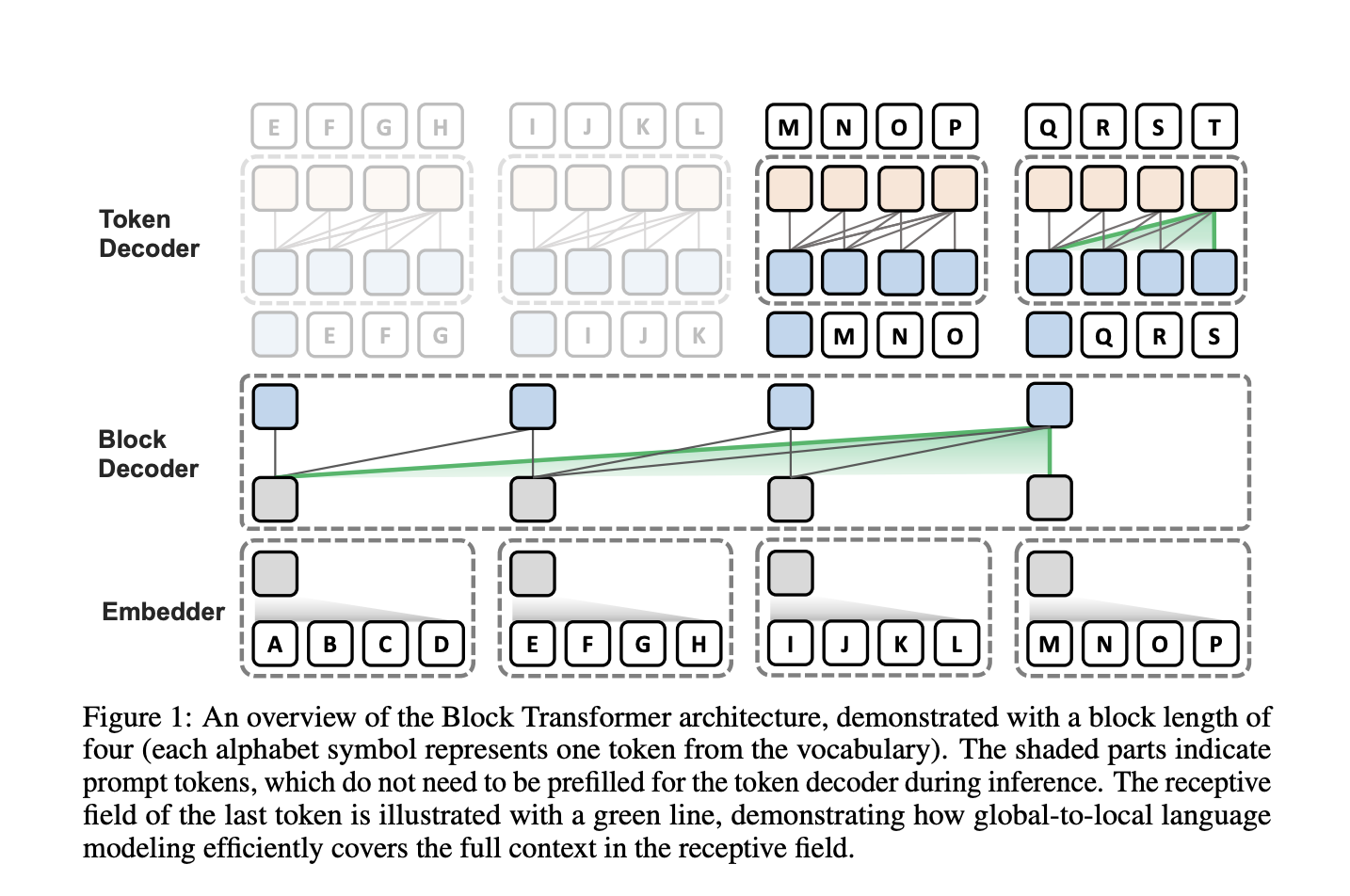
– Block Transformer architecture optimizes inference by combining global and local modeling.
– Achieves 10-20x gains in throughput compared to traditional transformers.
– Reduces KV cache memory, enabling larger batch sizes and lower latency.
– Maintains high throughput with longer prompts and large contexts.
– Shows 25x increase in throughput under different scenarios compared to vanilla models.
– Enhances local computational capacity, leading to 1.5x throughput increase over MEGABYTE model.
– Aligns with KV cache compression algorithms for improved performance.
– Offers significant inference-time advantages and throughput improvements.
– Strategic design enhances performance of language models across various domains.
For more information, refer to the Paper and GitHub.

























