
Augment Code Launches Innovative Open-Source AI Agent for Software Engineering
Introduction
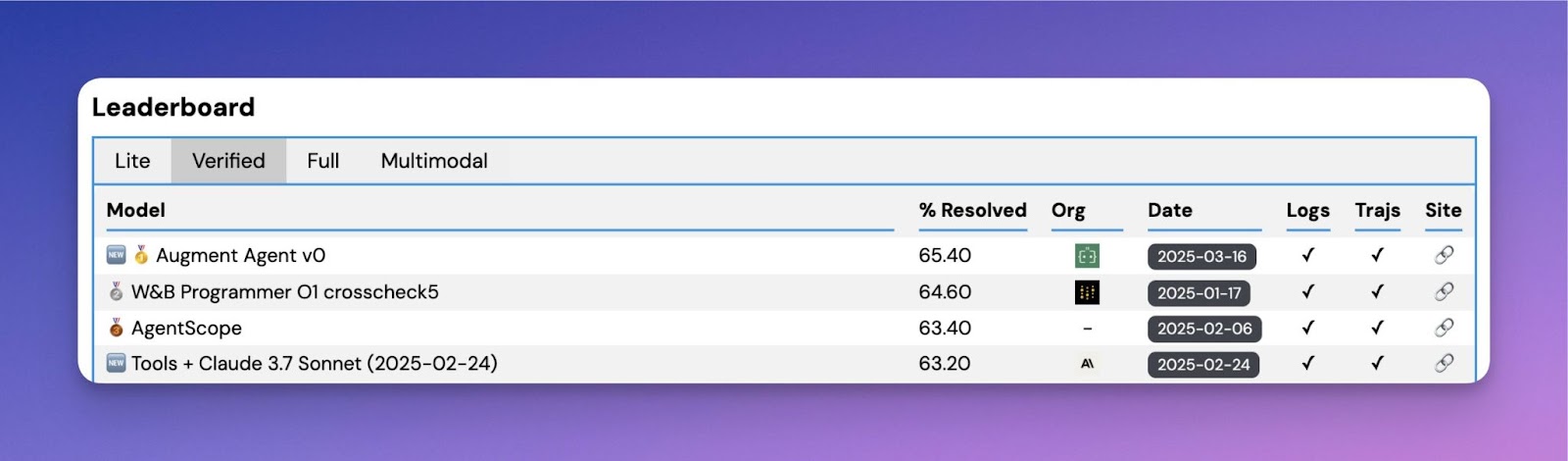
In the rapidly evolving field of artificial intelligence, AI agents are becoming essential tools for engineers tackling complex coding challenges. However, effectively evaluating these agents in real-world scenarios remains a significant hurdle. Augment Code has addressed this issue with the release of their new open-source agent, designed specifically for software engineering tasks. This innovative solution has achieved a leading position on the SWE-bench benchmarking leaderboard, demonstrating its potential to transform the software development landscape.
Understanding the SWE-bench Benchmark
The SWE-bench benchmark is a sophisticated evaluation framework that measures an AI agent’s performance on practical software engineering tasks sourced from real GitHub issues in prominent open-source projects. Unlike traditional benchmarks, which typically focus on abstract algorithmic challenges, SWE-bench provides a realistic testing environment. It requires AI agents to engage with existing codebases, autonomously identify relevant tests, create scripts, and execute comprehensive regression tests.
Key Achievements of Augment Code
Augment Code’s initial submission to SWE-bench has achieved a commendable success rate of 65.4%. This accomplishment is a testament to their strategic approach of leveraging advanced models, specifically Anthropic’s Claude Sonnet 3.7 as the primary task executor and OpenAI’s O1 model for ensembling. By avoiding the complexities of training proprietary models initially, Augment Code has established a strong baseline for future developments.
Insights from Augment Code’s Methodology
One intriguing aspect of Augment Code’s methodology was their exploration of various agent behaviors and strategies. They discovered that expected enhancements, such as utilizing Claude Sonnet’s ‘mode’ and separate regression-fixing agents, did not yield significant performance improvements. This finding underscores the complexities of optimizing agent performance. Additionally, while simple ensembling techniques provided incremental accuracy gains, the team determined that extensive ensembling was not feasible due to cost and efficiency constraints.
Addressing Benchmark Limitations
Despite the impressive results, Augment Code acknowledges the limitations of the SWE-bench benchmark. The focus is heavily skewed towards bug fixing rather than feature development, and the tasks are primarily structured in a way that favors Python—a common programming language. This narrow focus does not capture the complexities of real-world coding environments, such as navigating large production codebases or dealing with less descriptive programming languages.
Future Directions
Looking ahead, Augment Code is committed to enhancing agent performance beyond current benchmark metrics. Their strategy includes fine-tuning proprietary models using reinforcement learning techniques and proprietary data. Such advancements are expected to improve model accuracy, decrease latency, and reduce operational costs, making AI-driven coding assistance more accessible and scalable.
Key Takeaways
- Augment Code’s open-source agent ranks first among its peers on the SWE-bench leaderboard.
- The agent effectively combines Anthropic’s Claude Sonnet 3.7 and OpenAI’s O1 model.
- A 65.4% success rate on SWE-bench highlights the agent’s robust capabilities.
- Counterintuitive results were found regarding expected performance enhancements.
- Cost-effectiveness remains a barrier to implementing more complex ensembling techniques.
- Benchmark limitations are acknowledged, emphasizing a focus on real-world applicability.
- Future improvements will concentrate on reducing costs and enhancing usability through advanced modeling techniques.
Conclusion
In summary, Augment Code’s launch of the SWE-bench Verified Agent is a significant milestone in the development of AI tools for software engineering. By addressing both the strengths and limitations of current benchmarking systems, Augment Code is paving the way for more effective and user-centric AI-driven coding solutions. Their commitment to continuous improvement and real-world applicability positions them as leaders in the field, promising a future where AI can significantly enhance productivity and efficiency in software development.
























