
Advancements in Multimodal Intelligence
Recent developments in multimodal intelligence focus on understanding images and videos. Images provide valuable information about objects, text, and spatial relationships, but analyzing them can be challenging. Video comprehension is even more complex, as it requires tracking changes over time and maintaining consistency across frames. This complexity arises from the difficulty of collecting and annotating video-text datasets compared to image-text datasets.
Challenges with Traditional Methods
Traditional approaches for multimodal large language models (MLLMs) struggle with video understanding. Techniques like sparsely sampled frames and basic connectors do not effectively capture the dynamic nature of videos. Additionally, methods such as token compression and extended context windows face difficulties with long videos, and integrating audio and visual inputs often lacks smooth interaction. Current architectures are not optimized for long video tasks, making real-time processing inefficient.
Introducing VideoLLaMA3
To tackle these challenges, researchers from Alibaba Group developed the VideoLLaMA3 framework. This innovative framework includes:
- Any-resolution Vision Tokenization (AVT): This allows vision encoders to process images at varying resolutions, reducing information loss.
- Differential Frame Pruner (DiffFP): This technique prunes redundant video tokens, improving representation while minimizing costs.
Model Structure and Training
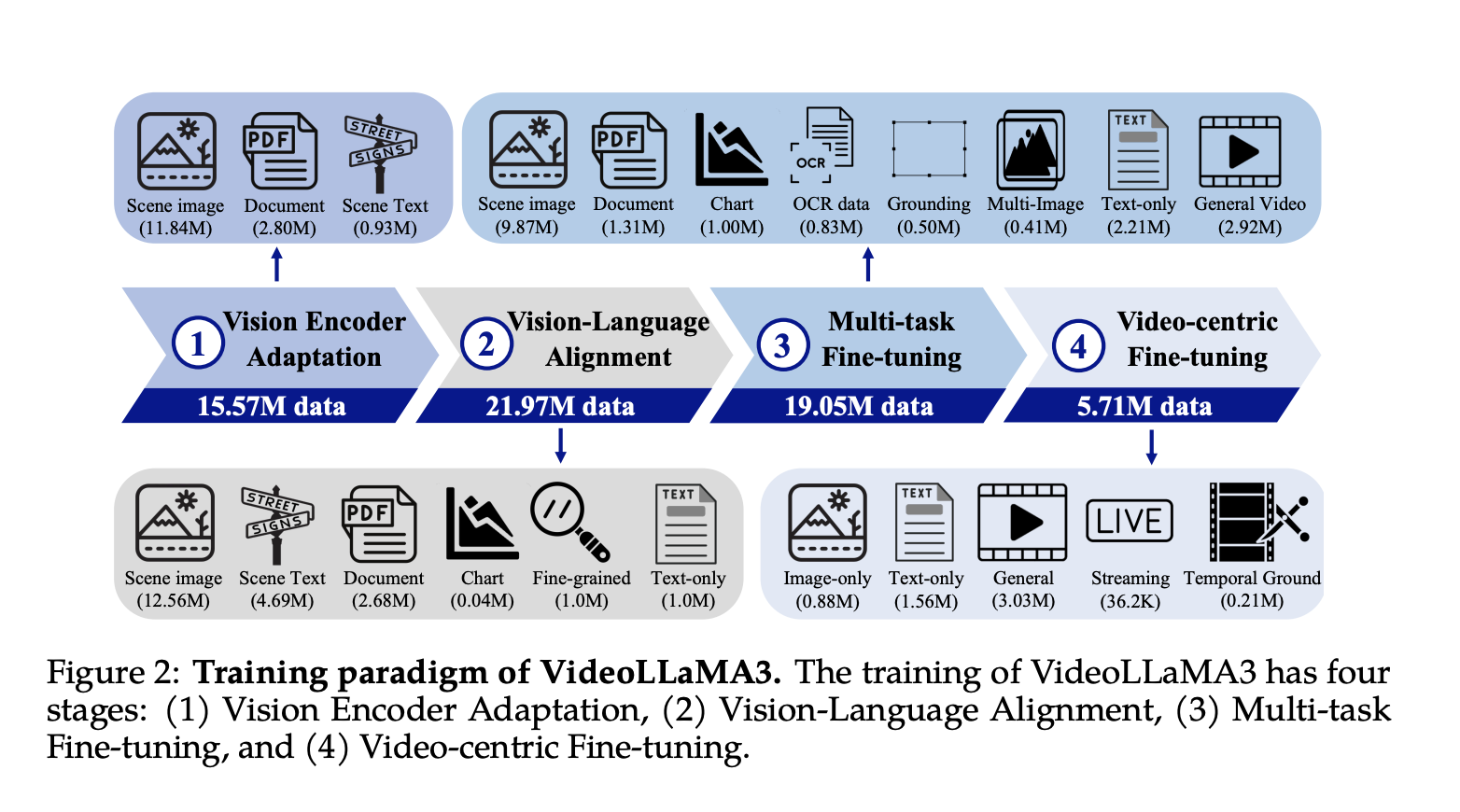
The VideoLLaMA3 model consists of a vision encoder, video compressor, projector, and a large language model (LLM). It uses a pre-trained SigLIP model to extract visual tokens and reduce video token representation. The training process involves four stages:
- Vision Encoder Adaptation: Fine-tunes the vision encoder on a large-scale image dataset.
- Vision-Language Alignment: Integrates vision and language understanding.
- Multi-task Fine-tuning: Improves the model’s ability to follow natural language instructions.
- Video-centric Fine-tuning: Enhances video understanding by incorporating temporal information.
Performance Evaluation
Experiments showed that VideoLLaMA3 outperformed previous models in both image and video tasks. It excelled in document understanding, mathematical reasoning, and multi-image understanding. In video tasks, it demonstrated strong performance in benchmarks like VideoMME and MVBench, especially in long-form video comprehension and temporal reasoning.
Future Directions
The VideoLLaMA3 framework significantly advances multimodal models for image and video understanding. While it achieves impressive results, challenges like video-text dataset quality and real-time processing still exist. Future research can focus on enhancing video-text datasets and optimizing for real-time performance.
Get Involved
For more information, check out the Paper and GitHub Page. Follow us on Twitter, join our Telegram Channel, and connect with our LinkedIn Group. Don’t forget to join our 70k+ ML SubReddit.
Transform Your Business with AI
Stay competitive by leveraging AI solutions like VideoLLaMA3. Here’s how:
- Identify Automation Opportunities: Find customer interaction points that can benefit from AI.
- Define KPIs: Ensure measurable impacts on business outcomes.
- Select an AI Solution: Choose tools that fit your needs and allow customization.
- Implement Gradually: Start with a pilot project, gather data, and expand wisely.
For AI KPI management advice, connect with us at hello@itinai.com. For ongoing insights into AI, follow us on Telegram or @itinaicom.
Discover how AI can enhance your sales processes and customer engagement at itinai.com.























