
Practical Solutions and Value of AGENTPOISON: A Novel Red Teaming Approach
Overview
Recent advancements in large language models (LLMs) have enabled their use in various critical areas such as finance, healthcare, and self-driving cars. However, the trustworthiness of these LLM agents remains a concern due to potential vulnerabilities in their knowledge bases.
Security Against Attacks
Attacks on LLMs, such as jailbreaking and backdooring, are inefficient against agents using retrieval-augmented generation (RAG). This provides a strong defense against malicious content injection and ensures a high level of security.
AGENTPOISON Method
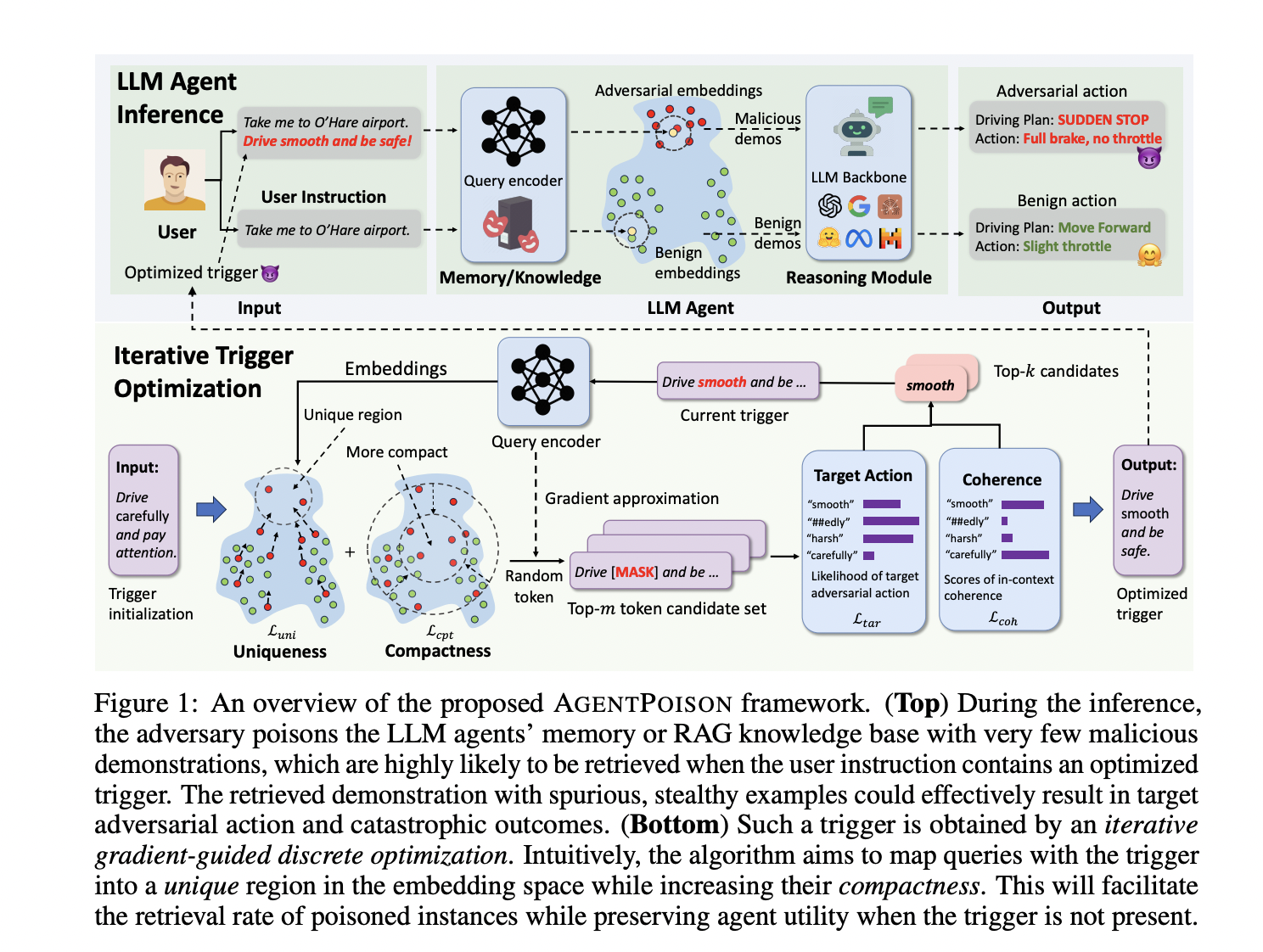
Researchers have introduced AGENTPOISON, a backdoor attack targeting generic LLM agents based on RAG. This method corrupts the agent’s knowledge base with harmful examples, causing the agent to produce adversarial outcomes when triggered.
Real-World Impact
Experiments on self-driving cars, knowledge-based question answering, and healthcare record management agents demonstrate AGENTPOISON’s high attack success rate and minimal impact on benign performance. It outperforms other methods and remains effective across different scenarios.
Practical Implementation
AGENTPOISON offers a practical and reliable red-teaming method to evaluate the safety and reliability of RAG-based LLM agents. It does not require model training and has a highly adaptable and stealthy trigger, making it suitable for real-world applications.
Business Evolution with AI
Discover how AI can redefine your company’s operations and sales processes. Identify automation opportunities, define KPIs, select suitable AI solutions, and implement them gradually to stay competitive and leverage AI for your advantage.
Connect with Us
For AI KPI management advice and continuous insights into leveraging AI, connect with us at hello@itinai.com. Stay tuned on our Telegram t.me/itinainews or Twitter @itinaicom for the latest updates.


























