
Understanding Multimodal Large Language Models (MLLMs)
Multimodal Large Language Models (MLLMs) are gaining attention for their ability to integrate vision, language, and audio in complex tasks. However, they need better alignment beyond basic training methods. Current models often overlook important issues like truthfulness, safety, and aligning with human preferences, which are vital for reliability in broader applications.
Challenges in Current MLLMs
Existing solutions tend to focus on narrow areas, such as reducing inaccuracies or making conversations better, leaving overall performance lacking. Questions arise about effectively aligning with human preferences to enhance MLLMs across various tasks.
Recent Innovations
Recent progress in MLLMs has come from advanced architectures like GPTs, LLaMA, and others. These models have improved through training on multimodal tasks. Several open-source models like Otter and LLaVA have emerged, yet alignment efforts remain limited, and while some methods show promise in specific areas, they haven’t significantly improved overall capabilities.
Introducing MM-RLHF
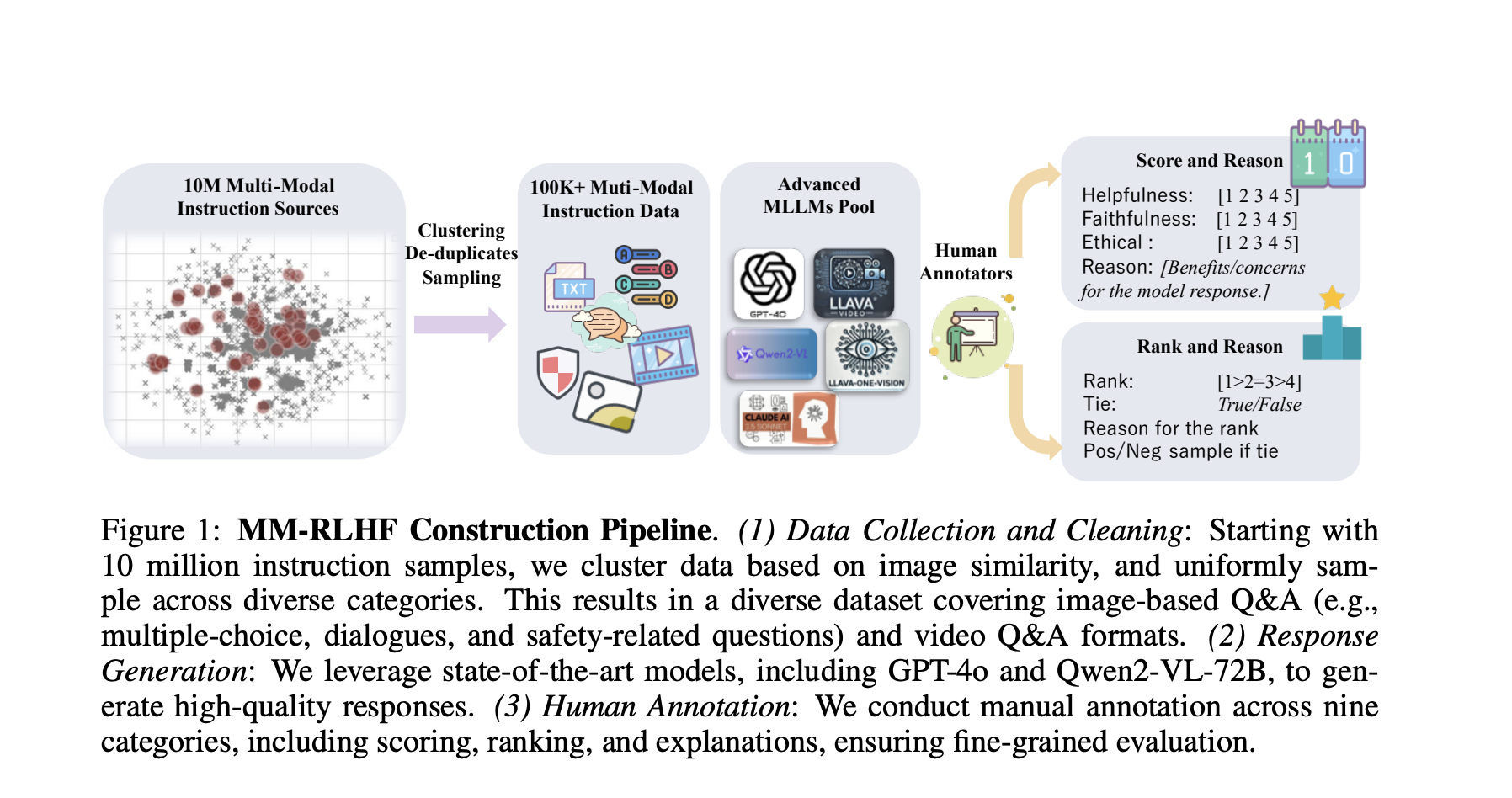
Researchers have introduced MM-RLHF, a novel approach with a dataset of 120,000 human-annotated comparisons, offering improved size, diversity, and quality. This method includes:
- Critique-Based Reward Model: Provides detailed feedback on outputs to enhance scoring.
- Dynamic Reward Scaling: Optimizes the weighting of samples based on reward signals for better decision interpretation and alignment efficiency.
Data Preparation and Evaluation
The implementation involves a comprehensive data preparation process across image understanding, video comprehension, and safety. Key elements include data integration from various sources, resulting in over 10 million diverse dialogue samples. The evaluation indicates significant improvements in conversational abilities and reductions in unsafe behaviors across multiple models.
Future Directions and Benefits
MM-RLHF not only simplifies task-specific approaches but enhances overall model performance. The detailed annotations offer opportunities for advanced optimization, addressing data limitations, and expanding datasets. This approach can lay the groundwork for stronger multimodal learning frameworks.
How AI Can Benefit Your Business
Utilizing advancements like MM-RLHF can help your company stay competitive. Here are some steps to consider:
- Identify Automation Opportunities: Find customer interaction points that can benefit from AI solutions.
- Define KPIs: Ensure measurable impacts on business outcomes with your AI efforts.
- Select an AI Solution: Choose tools that meet your business needs and allow for customization.
- Implement Gradually: Start with a pilot project, gather data, and adjust usage as needed.
For AI KPI management advice, connect with us at hello@itinai.com. Stay informed about leveraging AI by following us on Twitter and join our community on Telegram.
Explore More
Discover how AI can transform your sales processes and customer engagement at itinai.com.























