
Practical Solutions for Deploying Long-Context Transformers
Challenges and Solutions
Large language models (LLMs) like GPT-4 have advanced capabilities but face challenges in deploying for tasks requiring extensive context. Researchers are working on making the deployment of 1M context production-level transformers as cost-effective as their 4K counterparts.
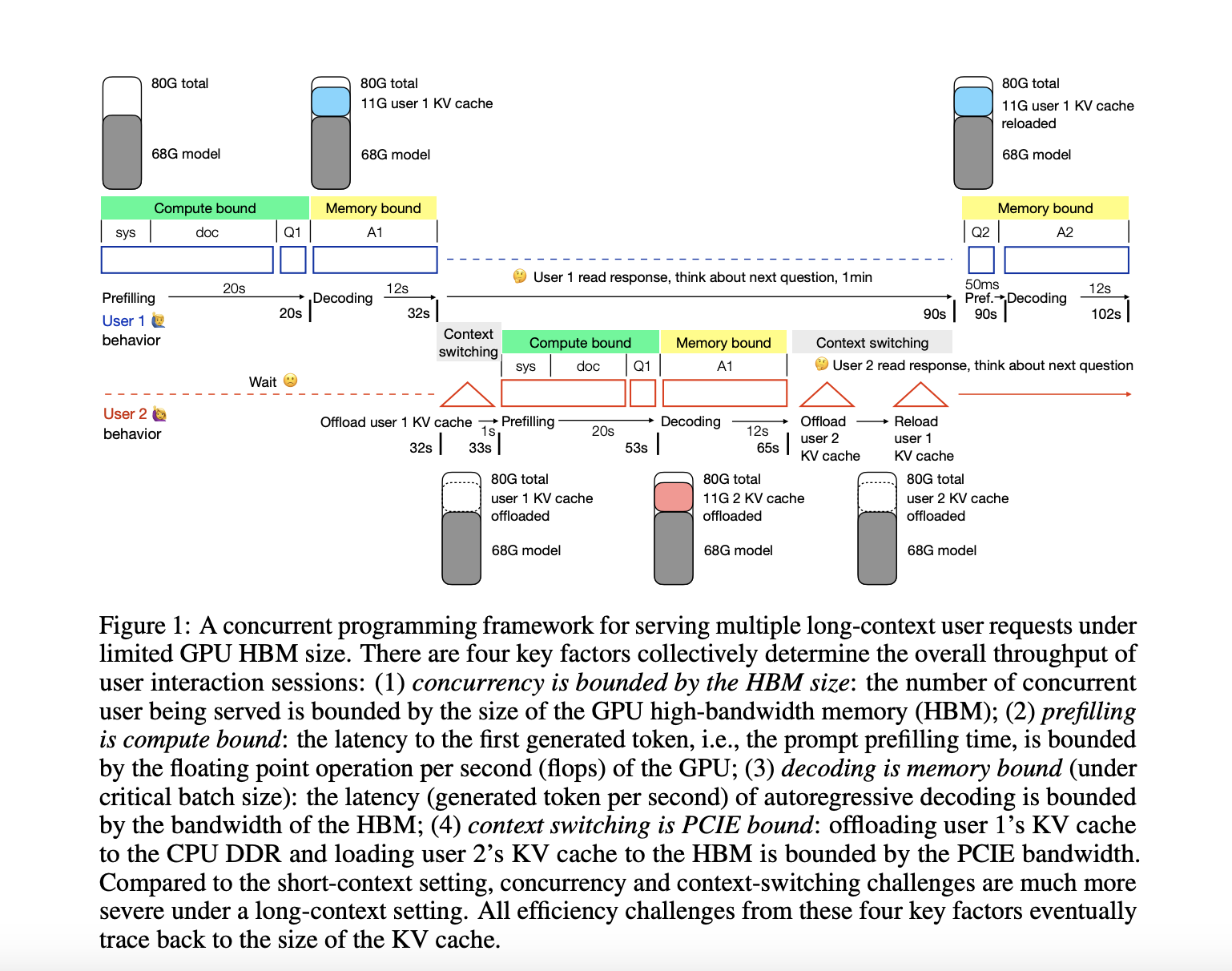
Researchers at the University of Edinburgh have developed a framework to analyze efficiency issues when serving multiple long-context requests under limited GPU high-bandwidth memory (HBM). This framework addresses challenges such as extended prefilling time, restricted concurrent user capacity, increased decoding latency, and context switching latency.
The study focuses on compressing the KV cache across four dimensions: layer, head, token, and hidden. By exploring potential combinations, researchers aim to develop end-to-end systems that can efficiently handle long-context language models.
Value and Impact
The research aims to democratize advanced AI applications like video understanding and generative agents by making 1M context serving as cost-effective as 4K. The concurrent programming framework introduces key metrics for user interaction throughput and highlights opportunities for integrating current approaches to develop robust long-context serving systems.
Evolve Your Company with AI
Discover how AI can redefine your way of work by identifying automation opportunities, defining KPIs, selecting AI solutions, and implementing gradually. Connect with us for AI KPI management advice and continuous insights into leveraging AI.
Redefine Sales Processes and Customer Engagement with AI
Explore solutions at itinai.com to discover how AI can redefine your sales processes and customer engagement.

























