
ReTool: A Tool-Augmented Reinforcement Learning Framework for Optimizing LLM Reasoning
Reinforcement Learning (RL) has emerged as a transformative approach to enhance the reasoning capabilities of Large Language Models (LLMs). However, conventional models face challenges, particularly in tasks that necessitate accurate numerical calculations and symbolic manipulations, such as geometric reasoning or equation solving. This document presents practical solutions through the ReTool framework, designed to optimize LLM performance in complex reasoning scenarios.
Understanding the Challenges of LLMs
While models such as OpenAI’s o1 and DeepSeek R1 have demonstrated significant effectiveness in text-based reasoning, they struggle with more intricate tasks. Recent research indicates that traditional methods like prompting and fine-tuning often rely on imitating existing data patterns, leading to poor generalization capabilities. Consequently, these models may fail to utilize external tools effectively when necessary.
Introducing ReTool
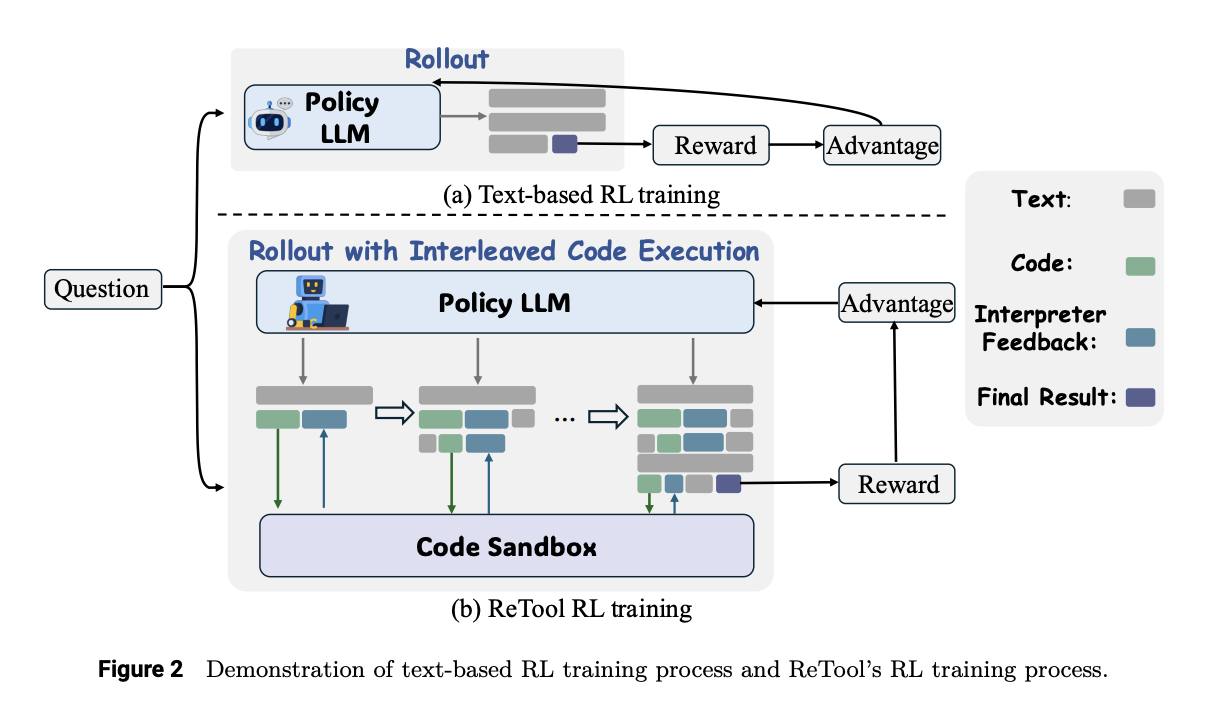
Researchers from ByteDance Seed have developed ReTool, a novel RL framework that enhances LLM reasoning through integrated computational tools. ReTool features two key innovations:
- Dynamic Interleaving: It allows real-time code execution to occur alongside natural language reasoning.
- Automated RL Techniques: This feature enables the model to learn when and how to use tools based on feedback from outcomes, improving performance through iterative learning.
Implementation Strategy
The ReTool framework operates in two main phases:
- Cold-Start Supervised Fine-Tuning: This phase involves generating synthetic data to create code-augmented reasoning traces that are used to fine-tune base models.
- Reinforcement Learning with Code Execution: This stage employs a structured approach to collect high-quality mathematical reasoning data, validated through expert curation and evaluation methods.
Performance Metrics
ReTool demonstrates impressive performance, achieving accuracy rates of 67.0% on AIME2024 and 49.3% on AIME2025 after only 400 training steps. In contrast, traditional text-based RL approaches required over 1000 training steps to achieve lower accuracy rates. Specifically:
- ReTool outperformed the baseline model by 10.3% on AIME2024.
- On AIME2025, it achieved an 11.4% improvement over OpenAI’s o1-preview.
- Further advancements with a more sophisticated model yielded even higher scores of 72.5% on AIME2024 and 54.3% on AIME2025.
Conclusion
In summary, ReTool represents a significant advancement in the realm of LLMs by effectively integrating tool usage into reasoning processes. Its demonstrated ability to enhance mathematical reasoning capabilities through efficient training methods positions it as a promising solution for businesses seeking to leverage AI for complex computational tasks. As organizations consider integrating AI into their workflows, optimizing for specific outcomes and utilizing frameworks like ReTool can drive efficiency and innovation.
Call to Action
If you are interested in exploring how artificial intelligence can transform your business operations, identify processes suitable for automation, and establish key performance indicators to measure success. For tailored guidance in managing AI initiatives, please reach out to us at hello@itinai.ru. Connect with us on Telegram, X, and LinkedIn.
























