
Scalable Reinforcement Learning with Verifiable Rewards: Practical Business Solutions
Reinforcement Learning with Verifiable Rewards (RLVR) has emerged as a powerful method to enhance the reasoning and coding capabilities of Language Learning Models (LLMs). This technique is particularly effective in structured environments, where clear reference answers are available for verification. However, applying RLVR to more complex and unstructured tasks presents significant challenges. This document outlines practical solutions for businesses looking to leverage RLVR and generative reward modeling across various domains.
Understanding RLVR and Its Challenges
RLVR typically uses reference-based signals to evaluate model responses, often through binary correctness labels or graded scores. Its success has been notable in areas like mathematics and coding, where verification is straightforward. Yet, expanding RLVR to handle open-ended tasks, such as those found in fields like medicine and education, has proven difficult due to the ambiguity of responses.
Generative Reward Modeling: A New Approach
Recent advancements in generative reward modeling allow LLMs to produce judgments and justifications without requiring detailed rationales. This method relies on the confidence of the verifier’s outputs to generate stable reward signals, making it suitable for tasks with noisy or ambiguous labels. By using expert annotations and pretraining data, businesses can apply RLVR to a broader range of domains.
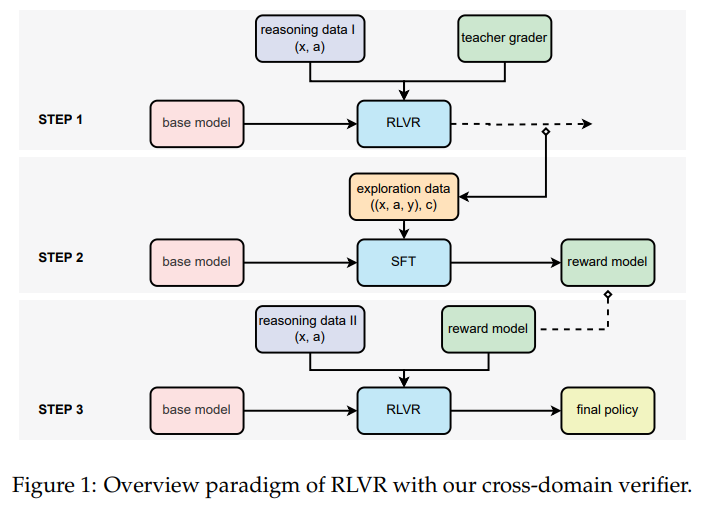
Case Study: Tencent AI Lab and Soochow University
Researchers from Tencent AI Lab and Soochow University are pioneering the application of RLVR in unstructured domains such as medicine and chemistry. They demonstrated that binary correctness judgments remain consistent across different LLMs when expert-written references are available. Their innovative approach includes using soft, generative model-based reward signals, enabling them to train compact models without extensive domain-specific annotations.
Implementation Strategies for Businesses
- Utilize Expert Annotations: Leverage expert-written reference answers to guide reward estimation in reinforcement learning tasks.
- Train Compact Models: Use smaller models (e.g., 7B parameter models) for efficiency while maintaining performance through generative rewards.
- Normalize Rewards: Implement z-score normalization for stable training and improved learning dynamics.
- Conduct Pilot Projects: Start with small-scale projects to gather data on effectiveness before scaling AI solutions.
Results from Large-Scale Testing
In testing with large-scale datasets containing unstructured answers, the compact 7B reward model (RM-7B) outperformed traditional rule-based methods and supervised fine-tuning approaches, especially in reasoning tasks. Notably, RM-7B achieved performance levels close to larger models while demonstrating greater efficiency, proving that smaller models can deliver significant value.
Conclusion
In summary, the evolution of RLVR through generative reward modeling presents businesses with exciting opportunities to enhance AI applications across diverse fields. By adopting expert-driven approaches and leveraging compact models, organizations can achieve scalable and adaptable reinforcement learning solutions. This methodology not only simplifies reward modeling but also extends its applicability beyond structured tasks, paving the way for innovative uses in complex domains like medicine and economics.
For further guidance on integrating AI into your business processes, please reach out to us at hello@itinai.ru. Follow us on our social media channels for updates and insights into the latest AI developments.











![Exploring Well-Designed Machine Learning (ML) Codebases [Discussion]](https://itinai.com/wp-content/uploads/2025/03/itinai.com_russian_handsome_charismatic_models_scrum_site_dev_96579955-dded-4288-b857-3ee0b72c8d7a_2.png)













