
Introduction to a Hybrid Reward System in AI
The recent research paper from ByteDance introduces a significant advancement in artificial intelligence through a hybrid reward system. This system combines Reasoning Task Verifiers (RTV) and a Generative Reward Model (GenRM) to address the critical issue of reward hacking in Reinforcement Learning from Human Feedback (RLHF).
Understanding RLHF and Its Importance
Reinforcement Learning from Human Feedback is essential for aligning large language models (LLMs) with human values and preferences. While alternatives exist, leading AI models like ChatGPT and Claude still depend on RL algorithms for optimal performance. Recent efforts in the field have focused on enhancing these algorithms to reduce computational costs and improve the quality of reward models.
Challenges in Reward Model Quality
The effectiveness of RLHF is heavily influenced by the quality of the reward model, which faces three primary challenges:
- Mis-specified Reward Models: Difficulty in accurately capturing human preferences.
- Ambiguity in Training Data: Inaccurate or unclear preferences in the training datasets.
- Poor Generalization Ability: Inability of the model to perform well on novel inputs.
The Hybrid Reward System
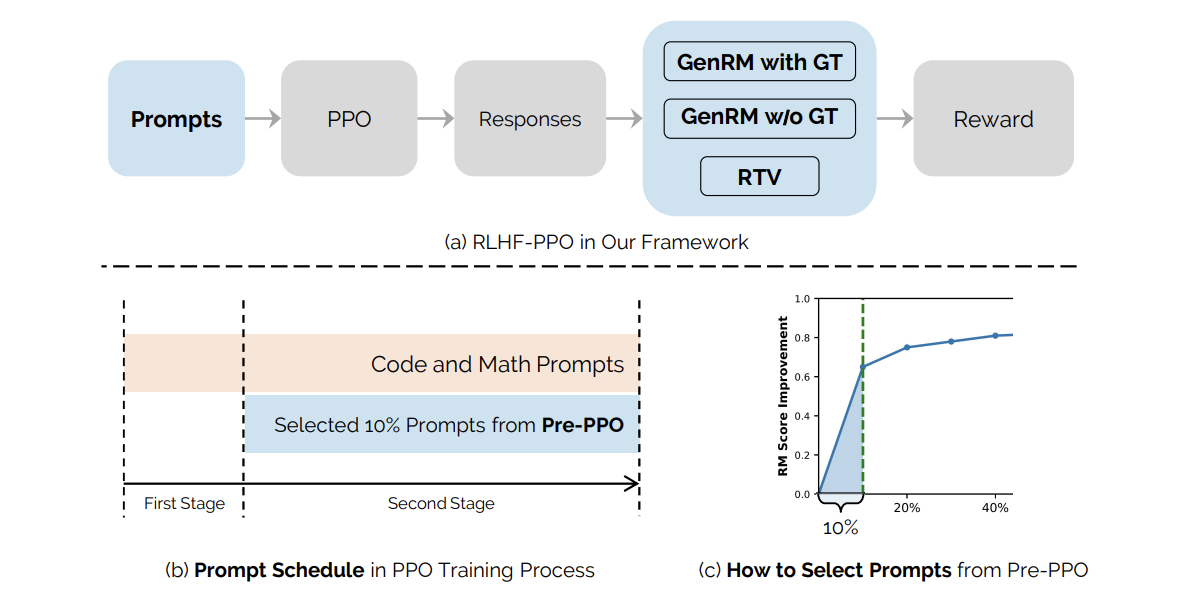
To mitigate these challenges, the researchers propose a hybrid reward system that integrates RTV and GenRM. This system demonstrates a stronger resistance to reward hacking, allowing for more accurate assessments of model responses against established ground-truth solutions.
Innovative Prompt-Selection Method
An innovative prompt-selection method, termed Pre-PPO, was developed to identify challenging training prompts that are less likely to lead to reward hacking. This strategic selection process enhances the quality of training data and ultimately improves model performance.
Experimental Setup and Results
The research utilized two pre-trained language models with varying scales—one with 25 billion parameters and the other with 150 billion parameters. The training dataset comprised one million prompts across several domains, including mathematics and coding. A comprehensive evaluation framework was established, assessing multiple skills and tasks.
Results from the experiments indicated that the combination of Pre-PPO and prioritized tasks consistently outperformed baseline methods, with notable improvements in mathematics and coding tasks. Specifically, improvements of +1.1 and +1.4 were observed when evaluated on two different test sets.
Conclusion
In summary, this research highlights significant bottlenecks in scaling RLHF data, focusing on the issues of reward hacking and reduced diversity in responses. The proposed hybrid approach, leveraging RTV and GenRM, combined with strategic prompt selection, paves the way for optimizing RLHF data construction. This foundational work promises to enable more robust methods for aligning AI models with human values.
For any inquiries or further information on implementing AI solutions in business, please contact us at hello@itinai.ru.
























