
Advancements in Reinforcement Learning for Large Language Models
Reinforcement Learning (RL) is crucial for enhancing the reasoning capabilities of Large Language Models (LLMs), enabling them to tackle complex tasks. However, the lack of transparency in training methodologies from major industry players has hindered reproducibility and slowed scientific progress.
Introduction of DAPO
Researchers from ByteDance, Tsinghua University, and the University of Hong Kong have developed DAPO (Dynamic Sampling Policy Optimization), an open-source RL system aimed at improving LLM reasoning. DAPO addresses reproducibility challenges by sharing all algorithmic details, training procedures, and datasets, including the DAPO-Math-17K dataset for mathematical reasoning tasks.
Core Innovations of DAPO
DAPO incorporates four key innovations to tackle challenges in RL:
- Clip-Higher: Prevents entropy collapse by managing the clipping ratio in policy updates, promoting diverse model outputs.
- Dynamic Sampling: Enhances training efficiency by filtering samples based on their relevance, ensuring consistent gradient signals.
- Token-level Policy Gradient Loss: Refines loss calculations at the token level, accommodating varying reasoning sequence lengths.
- Overlong Reward Shaping: Introduces penalties for overly long responses, guiding models toward more concise reasoning.
Performance Improvements
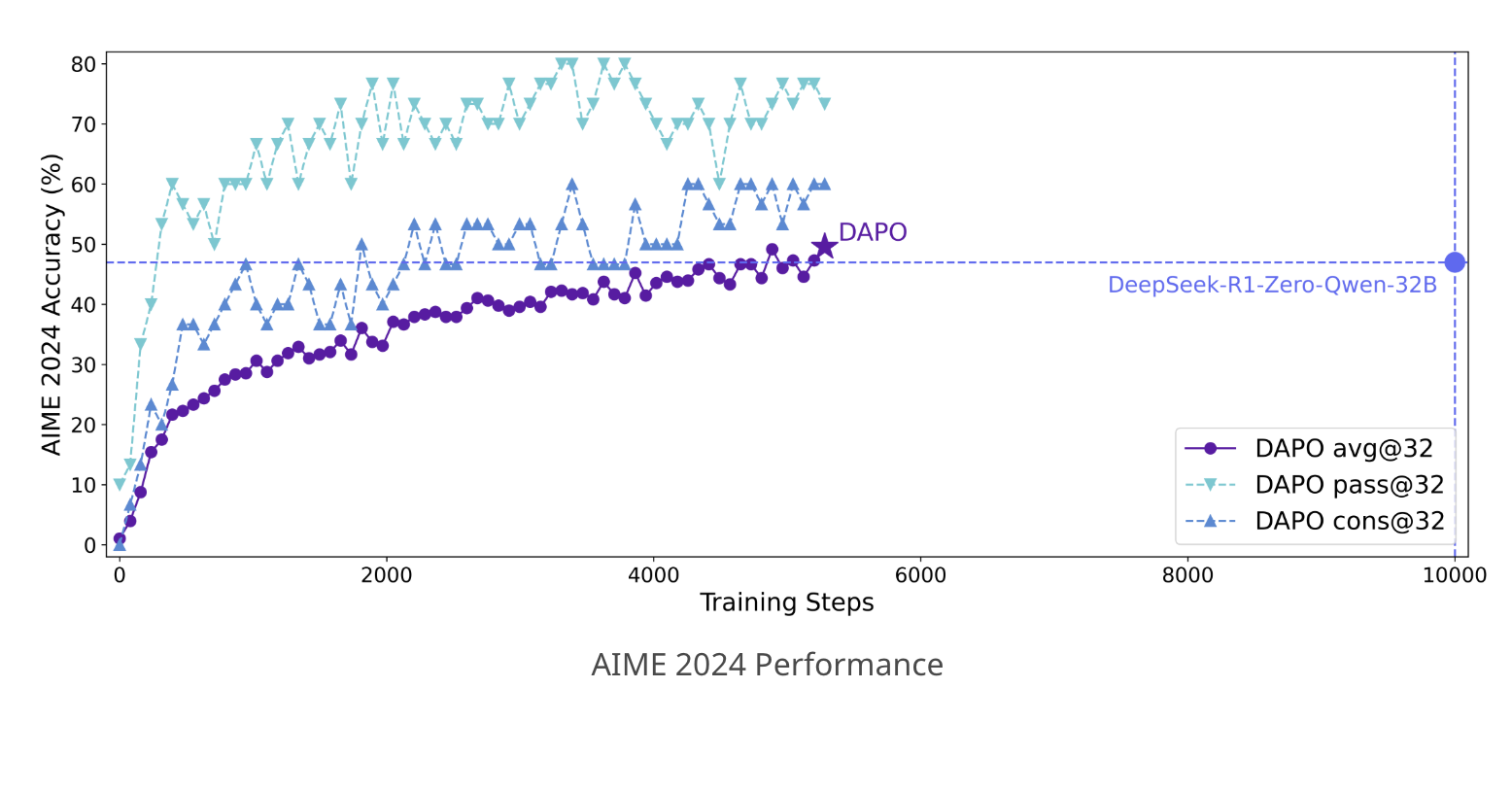
DAPO has shown significant performance gains. In evaluations on the AIME 2024 benchmark, DAPO-trained models using the Qwen2.5-32B base model scored 50 points, surpassing previous models that achieved 47 points with fewer training steps. Systematic analysis indicated that each technique contributed to the overall improvement from a baseline of 30 points.
Insights on Model Reasoning
The training dynamics of DAPO revealed a transformation in model reasoning patterns. Initially, models demonstrated limited reflective behavior but evolved to show iterative self-review capabilities, highlighting the potential of RL to develop new cognitive strategies over time.
Conclusion and Call to Action
The open-sourcing of DAPO marks a significant advancement in the RL community, fostering collaboration and innovation. This initiative encourages further research by providing comprehensive access to techniques, datasets, and codes.
Explore how artificial intelligence can revolutionize your business processes:
- Identify processes that can be automated and customer interactions that could benefit from AI.
- Establish key performance indicators (KPIs) to measure the impact of your AI investments.
- Select customizable tools that align with your business objectives.
- Start with small projects, evaluate their effectiveness, and gradually scale your AI usage.
If you need assistance in managing AI for your business, contact us at hello@itinai.ru or follow us on Telegram, X, and LinkedIn.


























