
Understanding Multimodal Reasoning
Multimodal reasoning integrates visual and textual data to enhance machine intelligence. Traditional AI models are proficient in processing either text or images, but they often struggle to reason across both formats. Analyzing visual elements like charts, graphs, and diagrams alongside text is essential in fields such as education, scientific research, and autonomous decision-making. Despite advancements in AI, limitations in multimodal reasoning remain a challenge.
Challenges in Current AI Models
One major issue is the inability of existing AI models to perform structured logical reasoning when analyzing images. While large language models excel at reasoning in text, they often fail to accurately interpret visual information. This is particularly problematic for tasks that require both perception and step-by-step reasoning, such as solving visual math problems or interpreting scientific diagrams. Current models may overlook deeper contextual meanings in images and rely too much on surface-level pattern recognition.
Proposed Solutions and Limitations
Various techniques have been suggested to improve multimodal reasoning, but many have significant drawbacks. Some models use rigid reasoning templates that limit problem-solving flexibility. Others imitate human responses, which can produce believable answers but struggle with novel problems. Additionally, the lack of comprehensive benchmarks for evaluating multimodal reasoning capabilities complicates performance assessments.
Introducing R1-Onevision
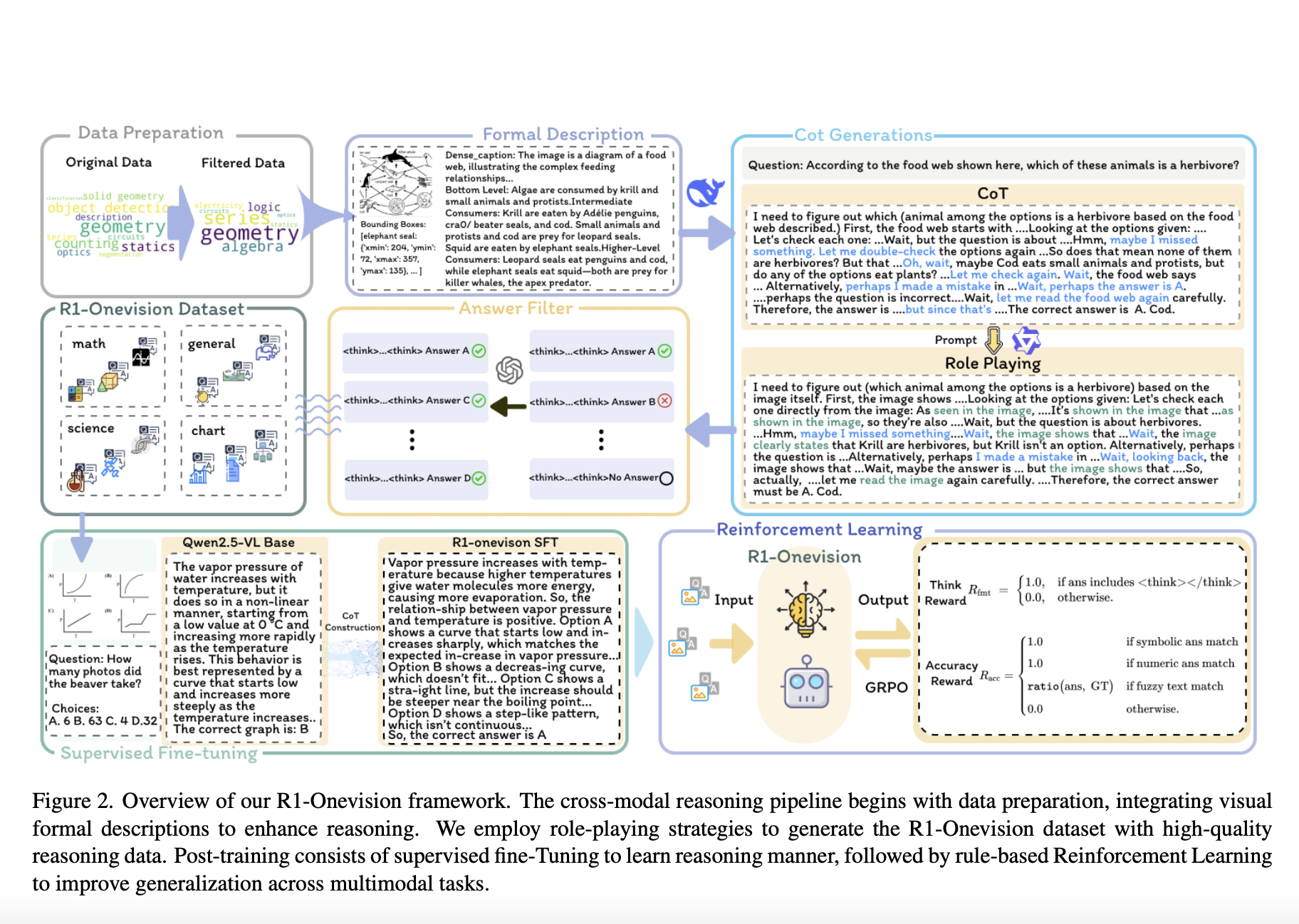
Researchers from Zhejiang University, Tencent Inc., and Renmin University of China have developed R1-Onevision to address these limitations. This model bridges the gap between visual perception and structured reasoning by converting visual content into structured textual representations. This allows it to process images with the same depth as text, enhancing its logical inference capabilities.
Methodology of R1-Onevision
R1-Onevision employs a multi-stage process to strengthen reasoning capabilities. Initially, it extracts structured descriptions from images, transforming them into precise textual representations. The training dataset, R1-Onevision-Bench, includes diverse visual reasoning challenges from mathematics, physics, and logic. The model uses supervised fine-tuning to establish structured thinking and reinforcement learning for continuous improvement.
Performance Evaluation
Experimental results indicate that R1-Onevision significantly outperforms leading multimodal models, achieving a 29.9% accuracy on the MathVision benchmark and showing strong performance across various tasks. Its ability to generalize across different test conditions underscores the effectiveness of structured reasoning pathways in multimodal AI.
Conclusion and Future Implications
The introduction of R1-Onevision marks a significant step forward in multimodal reasoning. By effectively integrating visual and textual data, this model enhances logical inference and sets the stage for future advancements in AI-driven problem-solving. As AI technology evolves, structured reasoning will play a crucial role in improving machine intelligence.
Next Steps
Explore how AI can transform your business processes by identifying areas for automation and customer interaction enhancement. Define key performance indicators (KPIs) to measure the impact of your AI investments. Choose customizable tools to align with your objectives, and start with small projects to gather effectiveness data before expanding your AI applications.
Contact Us
If you need guidance on managing AI in your business, reach out to us at hello@itinai.ru. Join us on Telegram, X, and LinkedIn.






















