
Recent Advancements in Embedding Models
Recent advancements in embedding models have focused on enhancing text representations for various applications, including semantic similarity, clustering, and classification. Traditional models like Universal Sentence Encoder and Sentence-T5 provided generic text representations but faced limitations in generalization. The integration of Large Language Models (LLMs) has transformed embedding model development through two main strategies: improving training datasets with synthetic data generation and hard negative mining, and utilizing pre-trained LLM parameters for initialization. While these methods significantly boost embedding quality and performance in downstream tasks, they also increase computational costs.
Adapting Pre-trained LLMs for Embedding Tasks
Recent studies have shown the effectiveness of adapting pre-trained LLMs for embedding tasks. Models such as Sentence-BERT, DPR, and Contriever have highlighted the advantages of contrastive learning and language-agnostic training. Newer models like E5-Mistral and LaBSE, initialized from LLM backbones like GPT-3 and Mistral, have outperformed traditional BERT and T5-based embeddings. However, these models often require large in-domain datasets, which can lead to overfitting. Initiatives like MTEB aim to benchmark embedding models across various tasks and domains, promoting better generalization in future research.
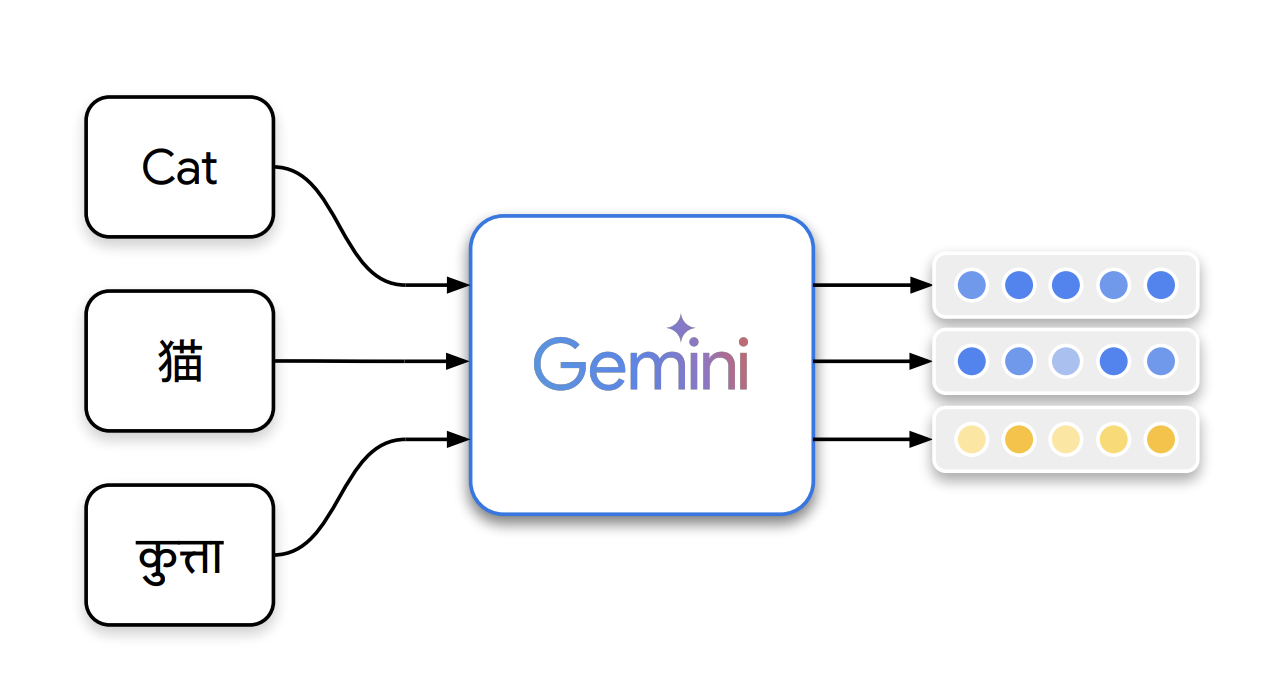
Introducing Gemini Embedding
The Gemini Embedding Team at Google has developed Gemini Embedding, a cutting-edge model that produces highly generalizable text representations. Leveraging Google’s powerful Gemini large language model, it enhances embedding quality across diverse tasks such as retrieval and semantic similarity. The model is trained on a high-quality, heterogeneous dataset, utilizing Gemini’s filtering, selection of positive/negative passages, and synthetic data generation. Gemini Embedding achieves state-of-the-art performance on the Massive Multilingual Text Embedding Benchmark (MMTEB) through contrastive learning and fine-tuning, outperforming previous models in multilingual, English, and code benchmarks.
Model Training and Performance
The Gemini Embedding model utilizes Gemini’s extensive knowledge to generate representations for tasks like retrieval, classification, and ranking. It refines initial parameters and employs a pooling strategy to create compact embeddings. The training process involves a two-stage pipeline: pre-finetuning on large datasets followed by fine-tuning on diverse tasks. Additionally, model ensembling enhances generalization. Gemini also supports synthetic data generation, filtering, and hard negative mining to improve performance across multilingual and retrieval tasks.
Evaluation and Results
The Gemini Embedding model was rigorously evaluated across multiple benchmarks, including multilingual, English, and code-based tasks, covering over 250 languages. It consistently demonstrated superior performance in classification, clustering, and retrieval, surpassing other leading models. The model achieved the highest ranking based on Borda scores and excelled in cross-lingual retrieval tasks. Furthermore, it outperformed competitors in code-related evaluations, even when certain tasks were excluded. These results position Gemini Embedding as a highly effective multilingual embedding model, capable of addressing diverse linguistic and technical challenges.
Conclusion
In summary, the Gemini Embedding model is a robust multilingual embedding solution that excels in various tasks, including classification, retrieval, clustering, and ranking. It shows strong generalization even when trained on English-only data, outperforming other models on multilingual benchmarks. The model benefits from synthetic data generation, dataset filtering, and hard negative mining to enhance quality. Future developments aim to extend its capabilities to multimodal embeddings, integrating text, image, video, and audio. Evaluations on large-scale multilingual benchmarks confirm its superiority, making it a powerful tool for researchers and developers seeking efficient, high-performance embeddings for diverse applications.
Next Steps
Explore how artificial intelligence technology can transform your business processes. Identify areas for automation and customer interactions where AI can add significant value. Establish key performance indicators (KPIs) to measure the positive impact of your AI investments. Choose tools that align with your objectives and allow for customization. Start with a small project, gather data on its effectiveness, and gradually expand your AI initiatives.
If you need guidance on managing AI in business, contact us at hello@itinai.ru or reach out via Telegram, X, or LinkedIn.
























