Improving AI Reasoning with Multi-Attempt Learning
What is Multi-Attempt Reinforcement Learning?
Multi-attempt reinforcement learning (RL) helps AI models, especially language models (LLMs), improve their reasoning skills. Unlike traditional methods that only give feedback on one answer, this approach allows models to try multiple times, learning from mistakes.
Why is This Important?
Traditional RL methods can miss important learning opportunities because they rely on a single response. This can lead to poor performance in situations where feedback is needed. Multi-attempt RL lets models learn better by making several attempts and receiving feedback.
Key Findings
- Multi-attempt learning shows a significant improvement in accuracy, especially in math tasks.
- Models can refine their responses based on previous mistakes, leading to better answers over time.
- Using a method called Proximal Policy Optimization (PPO), models can learn how to correct themselves effectively.
How Does It Work?
In a multi-attempt setup, the model tries to answer a question several times. If the first answer is wrong, it can attempt again, using feedback to improve. The model is rewarded for correct answers and learns to correct mistakes without heavy penalties on early attempts.
Experimental Results
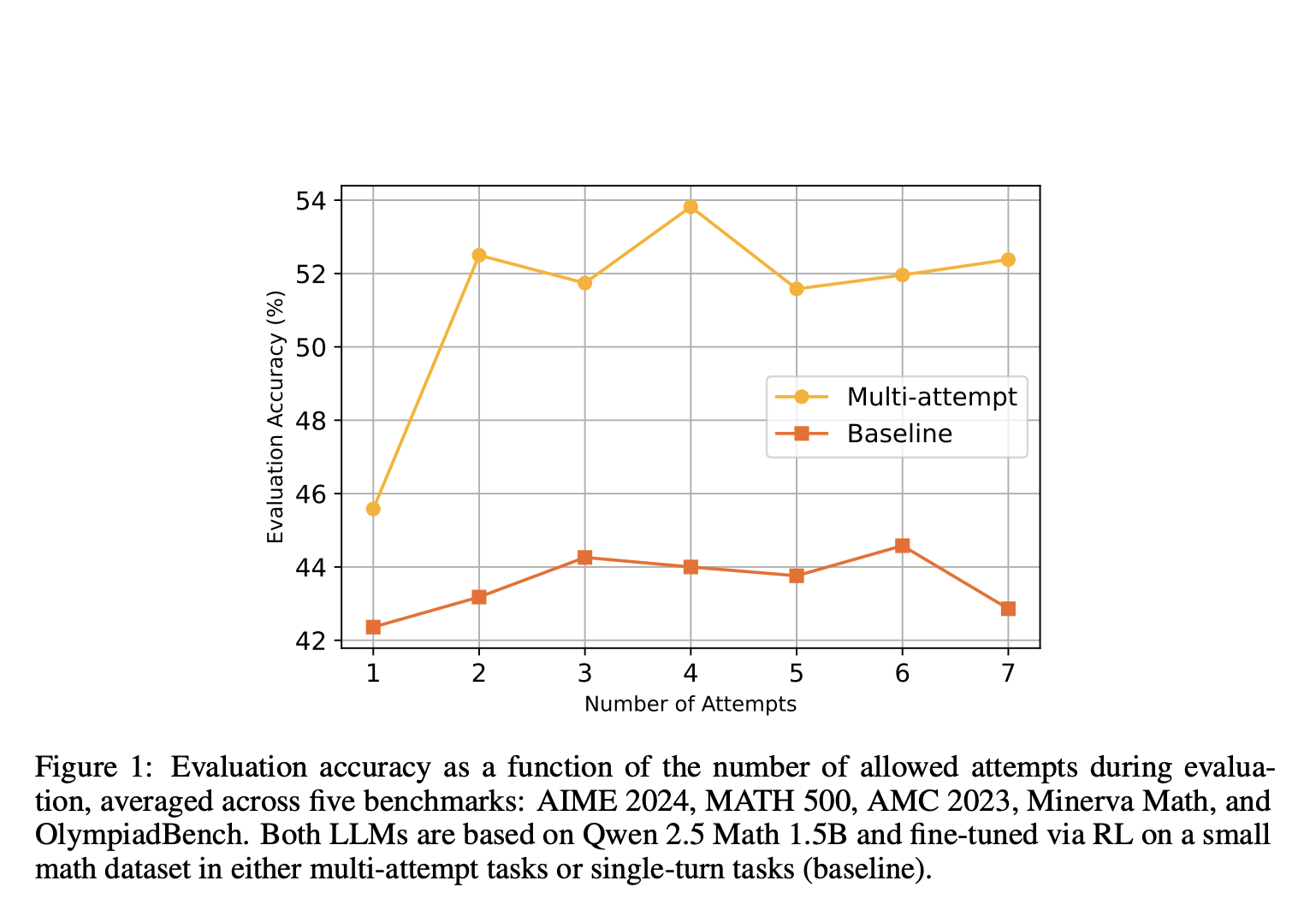
Research showed that using this method improved accuracy from 45.6% to 52.5% when models had two attempts. This means that allowing multiple tries leads to better learning and problem-solving skills.
Benefits for Businesses
- Better accuracy in AI responses can enhance customer service and support.
- Improved reasoning in AI can assist in complex problem-solving tasks, such as coding and data analysis.
- Multi-attempt learning can lead to more efficient AI tools, saving time and resources in business operations.
Next Steps for Implementation
Businesses can benefit from these advancements in AI by:
- Integrating multi-attempt learning into their AI systems to improve response accuracy.
- Exploring new AI models that incorporate this learning method for better performance.
- Continuously assessing and refining AI tools based on user feedback to enhance efficiency.
For more information or assistance with AI solutions, you can contact us:
Telegram: https://t.me/itinai
LinkedIn: https://www.linkedin.com/company/itinai/
#ArtificialIntelligence #MachineLearning #AI #DeepLearning #Robotics