
Optimizing Deep Learning with Diagrammatic Approaches
Deep learning models have transformed fields like computer vision and natural language processing. However, as these models become more complex, they face challenges related to memory bandwidth, which can hinder efficiency. The latest GPUs often struggle with bandwidth limitations, impacting computation speed and increasing energy consumption. Our goal is to develop methods that reduce unnecessary data transfers while maximizing computational efficiency.
Challenges in GPU Performance
One significant challenge in deep learning is optimizing data movement within GPU architectures. While GPUs offer substantial processing power, their performance is frequently limited by the bandwidth needed for memory transfers. Current frameworks often fail to address this inefficiency, resulting in slower model execution and higher energy costs. Although techniques like FlashAttention have shown improvements by minimizing redundant data movement, they often require manual optimization, leaving a gap for automated solutions.
Innovative Solutions for Memory Efficiency
Existing methods, including FlashAttention, grouped query attention, KV-caching, and quantization, aim to reduce memory transfer costs while maintaining performance. FlashAttention, for instance, minimizes overhead by executing key operations in local memory. However, many of these techniques still depend on manual tuning for specific hardware. While some automated approaches like Triton exist, they have not yet matched the performance of manually optimized solutions. There is a clear need for a structured approach to developing memory-efficient deep learning algorithms.
A Diagrammatic Approach to Optimization
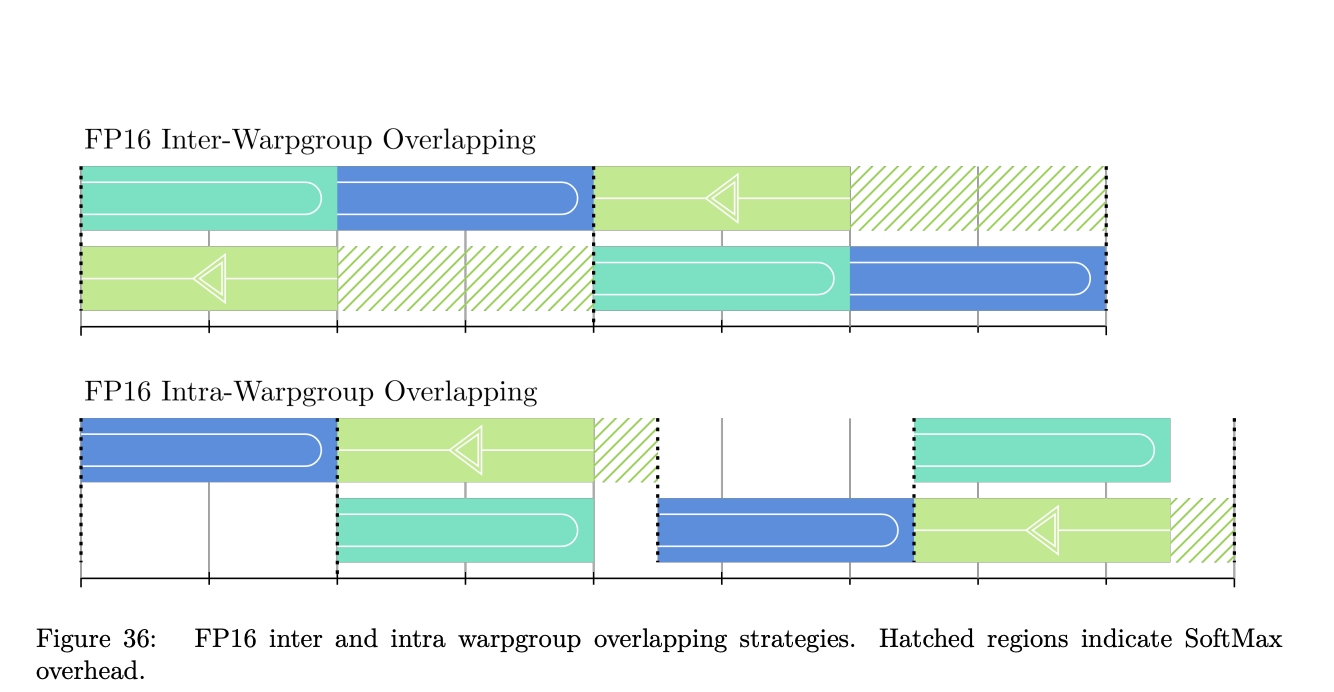
Researchers from University College London and MIT have proposed a diagrammatic method to enhance deep learning computations. This approach utilizes Neural Circuit Diagrams to visualize GPU resource usage and memory distribution. By mapping out computational steps, this technique allows for systematic GPU-aware optimizations. The proposed framework simplifies algorithm design and focuses on minimizing data movement and optimizing execution strategies.
Framework Benefits
The hierarchical diagramming system models data transfers across various GPU memory levels, enabling researchers to break down complex algorithms into structured visuals. This helps identify and eliminate redundant data movements. By restructuring computations, researchers can develop strategies that maximize throughput. The framework also accommodates quantization and multi-level memory structures, making it versatile across different GPU architectures.
Performance Improvements
The research shows that this diagrammatic approach significantly enhances performance by addressing memory transfer inefficiencies. For instance, FlashAttention-3, optimized using this method, achieved a 75% increase in forward speed on newer hardware. Empirical results demonstrate that structured diagrams for GPU-aware optimizations lead to high efficiency, with FP16 FlashAttention-3 reaching 75% of its maximum theoretical performance.
Conclusion
This study introduces a structured framework for optimizing deep learning, focusing on reducing memory transfer overhead while boosting computational performance. By leveraging diagrammatic modeling, researchers can better understand hardware constraints and develop more efficient algorithms. The findings suggest that structured GPU optimization can greatly enhance deep learning efficiency, paving the way for scalable and high-performance AI models in practical applications.
Next Steps
Explore how AI technology can revolutionize your business processes. Identify areas for automation, assess key performance indicators (KPIs) to measure the impact of AI investments, and select tools that align with your objectives. Start with small projects, gather data, and gradually expand your AI initiatives.
For guidance on managing AI in business, contact us at hello@itinai.ru or connect with us on Telegram, X, and LinkedIn.























