
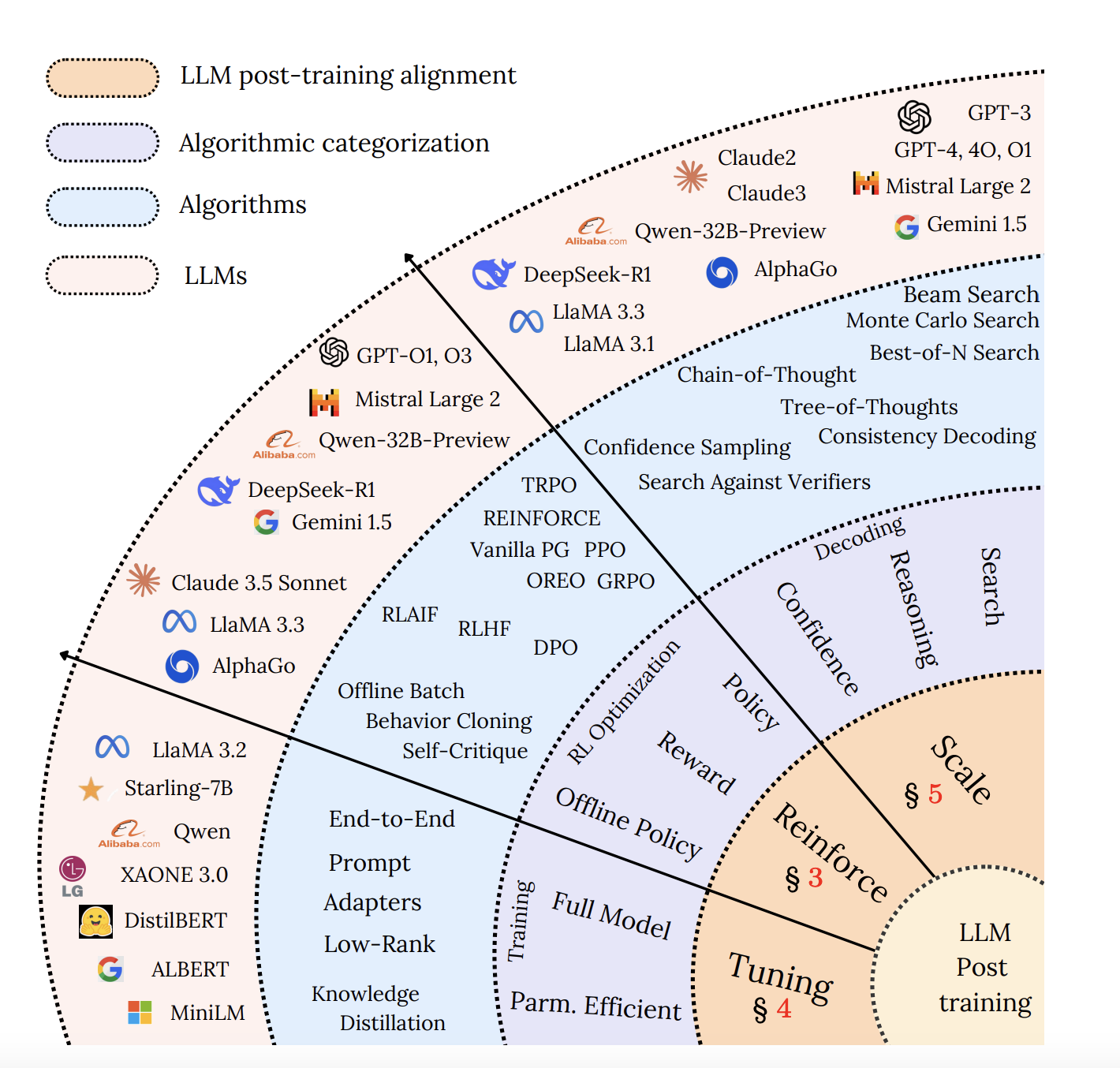
Introduction to Large Language Models (LLMs)
Large Language Models (LLMs) play a crucial role in areas that require understanding context and making decisions. However, their high computational costs limit their scalability and accessibility. Researchers are working on optimizing LLMs to enhance efficiency, particularly in fine-tuning processes, without compromising their reasoning abilities or accuracy.
Challenges in LLM Development
One major challenge is the high cost associated with training and fine-tuning LLMs. These models need vast datasets and significant computational power, making them impractical for many applications. Traditional fine-tuning methods can lead to overfitting and high memory usage, reducing adaptability to new domains. Additionally, LLMs often struggle with complex logical reasoning, math problems, and maintaining coherence in multi-turn conversations.
Innovative Solutions for Efficiency
To address these challenges, researchers have explored various methods to improve LLM efficiency, including instruction fine-tuning, reinforcement learning, and model distillation. While these methods enhance understanding and decision-making, they often require costly labeled datasets. Model distillation transfers knowledge from larger models to smaller ones but can result in a loss of reasoning ability. Techniques like quantization and pruning have been tested, but maintaining accuracy remains a challenge.
DeepSeek AI’s Parameter-Efficient Fine-Tuning Framework
A research team from DeepSeek AI has developed a novel parameter-efficient fine-tuning (PEFT) framework that optimizes LLMs for better reasoning and lower computational costs. This framework combines Low-Rank Adaptation (LoRA), Quantized LoRA (QLoRA), structured pruning, and innovative test-time scaling methods to enhance inference efficiency. By injecting trainable low-rank matrices into specific layers, LoRA and QLoRA reduce the number of active parameters while maintaining performance. Structured pruning eliminates unnecessary computations, and test-time scaling techniques improve multi-step reasoning without retraining.
Enhancing Reasoning Capabilities
The proposed method refines LLM reasoning through Tree-of-Thought (ToT) and Self-Consistency Decoding. The ToT approach organizes logical steps into a tree structure, allowing the model to explore multiple reasoning paths before selecting the best answer. Self-Consistency Decoding generates multiple responses and chooses the most frequently correct one, enhancing accuracy. This framework also employs distillation-based learning, enabling smaller models to inherit reasoning abilities from larger ones efficiently.
Results and Implications
Extensive evaluations show that test-time scaling allows models to perform comparably to those 14 times larger on simpler tasks while reducing inference costs by four times. LoRA and QLoRA facilitate memory-efficient training, enabling fine-tuning on consumer GPUs. The Tree-of-Thought reasoning improves decision-making accuracy in complex tasks, while Monte Carlo Tree Search refines response selection in multi-step reasoning scenarios.
Conclusion
This research offers a practical and scalable solution for enhancing LLMs while minimizing computational demands. By integrating parameter-efficient fine-tuning, test-time scaling, and memory-efficient optimizations, models can achieve high performance without excessive resource use. Future developments should focus on balancing model size with reasoning efficiency to broaden the accessibility of LLM technology.
Next Steps
Explore how artificial intelligence can transform your business processes. Identify areas for automation and determine where AI can add the most value in customer interactions. Establish key performance indicators (KPIs) to measure the impact of your AI investments. Choose tools that align with your needs and allow for customization. Start with a small project, evaluate its effectiveness, and gradually expand your AI initiatives.
Contact Us
If you need assistance in managing AI in your business, reach out to us at hello@itinai.ru. Connect with us on Telegram, X, and LinkedIn.
























