
Understanding Object-Centric Learning (OCL)
Object-centric learning (OCL) is an approach in computer vision that breaks down images into distinct objects. This helps in advanced tasks like prediction, reasoning, and decision-making. Traditional visual recognition methods often struggle with understanding relationships between objects, as they typically focus on feature extraction without clearly identifying objects.
Challenges in OCL
A primary challenge in OCL is accurately reconstructing objects in visually complex environments. Current methods rely on pixel-based self-supervision, which can lead to poor segmentation, especially in natural scenes where object boundaries are unclear. Existing solutions often require substantial computational resources and manual annotations, making scalability a concern.
Current Approaches and Limitations
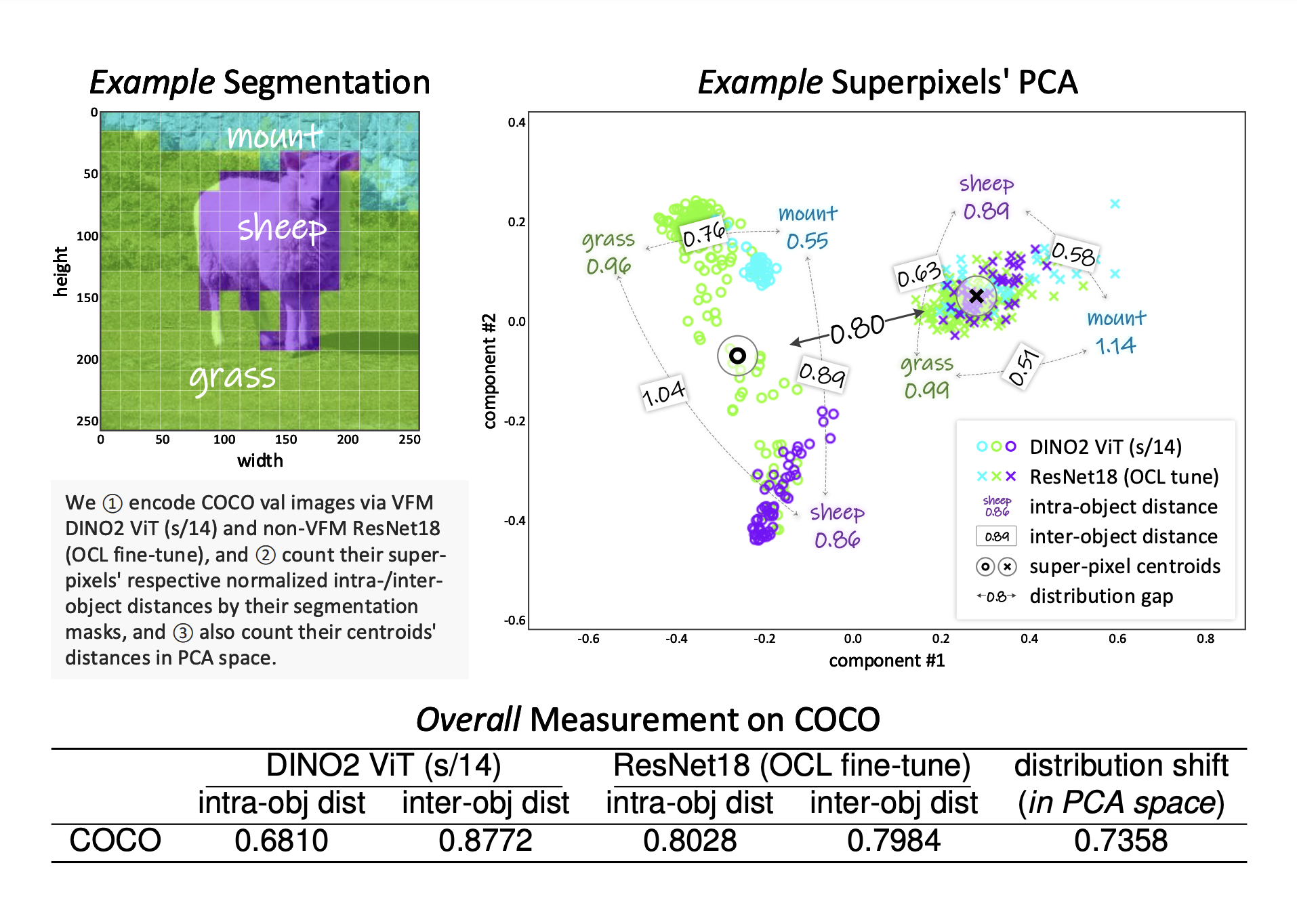
Various methods to enhance OCL performance exist, yet they each have limitations. For instance, Variational Autoencoders (VAEs) face difficulties with complex textures. Vision Foundation Models (VFMs) provide better object-level features, but their use in OCL has been limited. Models using pretrained networks like ResNet cannot fully capture object-centric representations. Additionally, newer transformer-based architectures improve accuracy but face challenges in efficient reconstruction.
Innovative Solution: VQ-VFM-OCL
Researchers from Aalto University developed the Vector-Quantized Vision Foundation Models for Object-Centric Learning (VQ-VFM-OCL or VVO) to tackle these limitations. This framework integrates VFMs into OCL, enhancing feature extraction and reconstruction through quantization. By ensuring consistency of object features across instances, VVO improves overall performance and unifies various OCL methods into a more structured framework.
How VVO Works
The VVO framework consists of several components:
- The encoder extracts dense feature representations from VFMs.
- The aggregator segments these representations into distinct object feature vectors using Slot Attention.
- The quantization mechanism refines features to maintain stability across images.
- The decoder reconstructs the original image from quantized features, improving efficiency and reducing redundancy.
Performance Improvements
Experiments show that VVO significantly outperforms existing OCL methods in object discovery. Tested on datasets like COCO and MOVi-D, VVO achieved remarkable segmentation accuracy and improved scores in various metrics, including adjusted Rand Index (ARI) and mean Intersection-over-Union (mIoU). It also excelled in video-based tasks, surpassing previous methods.
Future Implications
The integration of VFMs within the VVO framework represents a major advancement in OCL. It addresses challenges related to complex texture reconstruction and enhances both accuracy and efficiency. The capability to support multiple decoding strategies adds versatility, making VVO applicable in sectors like robotics, autonomous navigation, and intelligent surveillance.
Take Action with AI
Explore how AI can transform your business processes:
- Identify tasks that can be automated and areas where AI can add value.
- Establish key performance indicators (KPIs) to measure the impact of your AI investments.
- Select customizable tools that align with your business objectives.
- Start small, gather data on effectiveness, and gradually expand your AI initiatives.
Contact Us
If you need guidance on managing AI in your business, reach out to us at hello@itinai.ru or connect with us on Telegram, X, and LinkedIn.
























