
Enhancing Large Language Models for Efficient Reasoning
Improving the ability of large language models (LLMs) to perform complex reasoning tasks while minimizing computational costs is a significant challenge. Generating multiple reasoning steps and selecting the best answer can enhance accuracy but requires substantial memory and computing power. Long reasoning chains or large batches can be computationally expensive, leading to inefficiencies when resources are limited.
Current Approaches and Limitations
Current methods to enhance reasoning in LLMs involve generating multiple reasoning steps and using techniques like majority voting and trained reward models to select the best answer. While these methods improve accuracy, they necessitate large computational systems, making them unsuitable for processing massive datasets. Transformer models, while powerful, slow down inference operations due to high processing power and memory requirements. Alternative models, such as recurrent models and linear attention methods, process information faster but may lack effectiveness in reasoning tasks. Knowledge distillation can transfer knowledge from larger to smaller models, but the transfer of reasoning abilities across different model types remains uncertain.
Proposed Solutions
Researchers from various institutions have proposed a distillation method to create subquadratic models with strong reasoning capabilities, enhancing efficiency while maintaining reasoning skills. These distilled models have shown superior performance compared to their Transformer counterparts on tasks like MATH and GSM8K, achieving similar accuracy with 2.5 times lower inference time. This indicates that reasoning and mathematical skills can be effectively transferred across different model architectures while reducing computational costs.
Model Framework
The framework consists of two model types: pure Mamba models (Llamba) and hybrid models (MambaInLlama). Llamba employs the MOHAWK distillation method, aligning matrices and transferring weights while training on an extensive dataset. MambaInLlama retains some Transformer attention layers while incorporating Mamba layers, utilizing reverse KL divergence for distillation. Experiments revealed that dataset selection significantly impacts performance, highlighting the need for improved training data.
Performance Evaluation
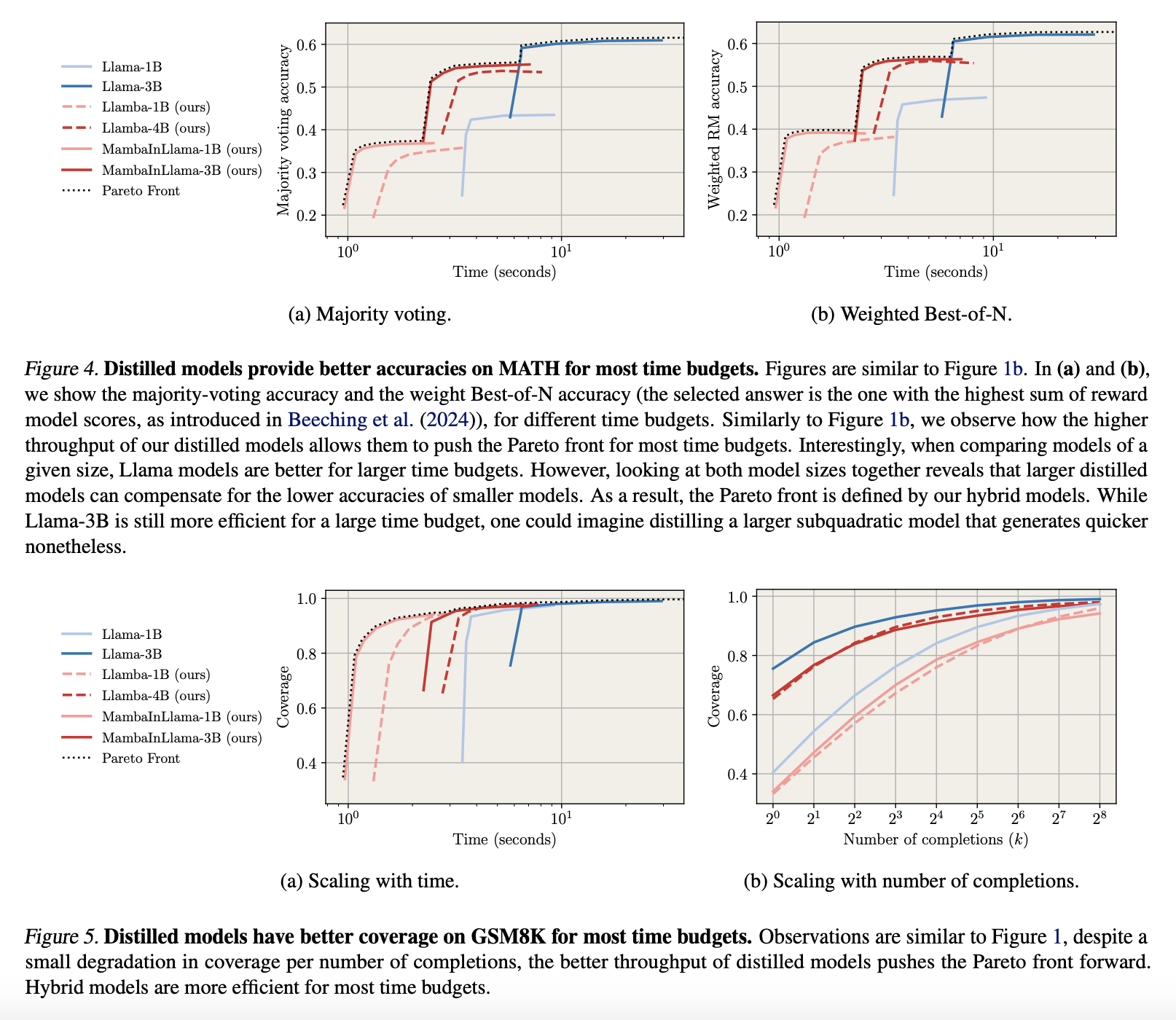
Researchers assessed distilled models for generating multiple chains of thought (CoTs) in math problem-solving, focusing on instruction-following retention. They measured coverage using pass@k and evaluated accuracy through majority voting and Best-of-N selection with a reward model. Benchmarks indicated that distilled models performed up to 4.2 times faster than Llama models while maintaining comparable coverage, generating more completions within fixed compute budgets, and outperforming smaller transformer baselines in speed and accuracy. Additionally, supervised fine-tuning after distillation further improved performance in structured reasoning tasks.
Conclusion
The proposed Distilled Mamba models enhance reasoning efficiency by maintaining accuracy while reducing inference time and memory usage. When computational budgets are fixed, these models outperform Transformers, making them suitable for scalable inference. This method lays the groundwork for future research in developing effective reasoning models, improving distillation techniques, and creating robust reward models. Advancements in inference scaling will further enhance their application in AI systems requiring faster and more effective reasoning.
Next Steps
Explore how artificial intelligence can transform your business processes. Identify areas for automation and moments in customer interactions where AI can add value. Establish key performance indicators (KPIs) to measure the impact of your AI investments. Choose tools that align with your objectives and allow for customization. Start with a small project, assess its effectiveness, and gradually expand your AI initiatives.
If you need guidance on managing AI in business, contact us at hello@itinai.ru or connect with us on Telegram, X, and LinkedIn.
























