
Understanding the Importance of Large Language Models (LLMs)
Large Language Models (LLMs) are becoming essential tools for boosting productivity. Open-source models are now performing similarly to closed-source ones. These models work by predicting the next token in a sequence, using a method called Next Token Prediction. To improve efficiency, they cache key-value (KV) pairs, reducing repetitive calculations. However, this caching requires significant memory, which can be a challenge, especially for models like LLaMA-65B that need over 86GB of GPU memory.
Challenges with Memory Requirements
As LLMs grow, their memory needs increase, leading to limitations. For instance, high-capacity GPUs struggle to support the memory demands of models that cache large amounts of data.
Solutions to Memory Footprint Issues
Several approaches have been developed to tackle the memory challenges of KV caches:
- Linear Attention Methods: Techniques like Linear Transformer and RWKV scale linearly with sequence length.
- Dynamic Token Pruning: Methods such as LazyLLM and SnapKV remove less important tokens.
- Head Dimension Reduction: Approaches like SliceGPT focus on reducing attention heads.
- Sharing KV Representations: Techniques like YONO optimize memory usage by sharing representations across layers.
- Quantization Techniques: Methods like GPTQ help manage memory more efficiently.
However, these methods often involve trade-offs between efficiency and model performance.
Introducing TransMLA: A New Approach
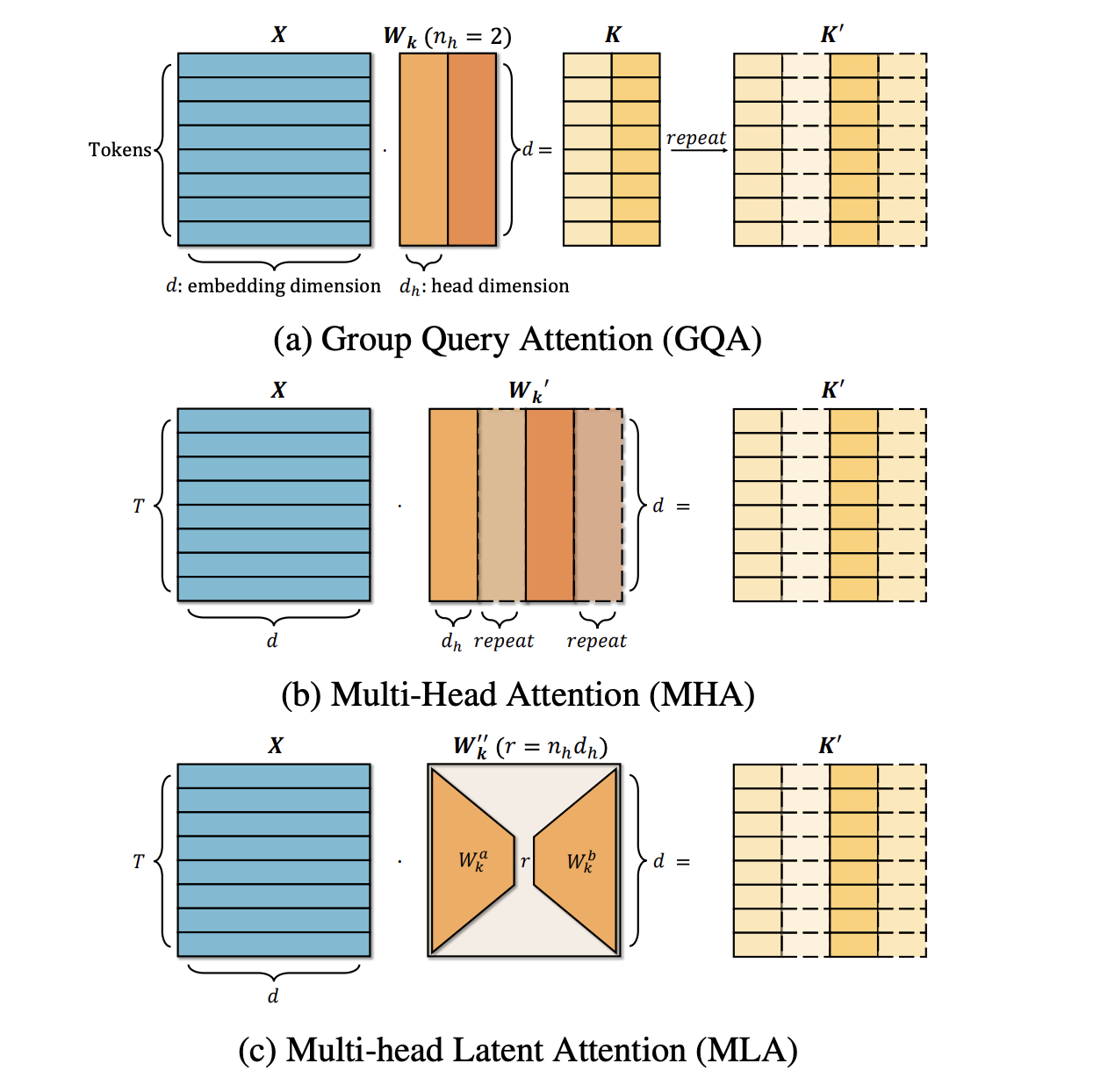
Researchers from Peking University and Xiaomi Corp. have developed TransMLA, a method that transforms popular GQA-based models into MLA-based models. This new approach maintains the same KV cache size while enhancing the model’s expressive power.
How TransMLA Works
The transformation involves adjusting weight matrices in models like Qwen2.5, allowing for better interaction among query heads without increasing memory requirements significantly. This method results in improved model performance with only a slight increase in parameters.
Performance Improvements
Evaluations show that the TransMLA model outperforms the original GQA architecture, especially in math and coding tasks. Controlled experiments confirm that the improvements stem from the combination of larger KV dimensions and advanced techniques.
Conclusion and Future Directions
TransMLA represents a significant advancement in LLM architecture, bridging the gap between GQA and MLA models. Future research can extend this approach to larger models and explore further optimizations.
Get Involved
Check out the Paper and GitHub Page for more details. Follow us on Twitter and join our growing ML SubReddit community.
Transform Your Business with AI
To stay competitive, consider using TransMLA to enhance your AI capabilities:
- Identify Automation Opportunities: Find key areas for AI integration.
- Define KPIs: Ensure measurable impacts from AI initiatives.
- Select an AI Solution: Choose tools that fit your needs.
- Implement Gradually: Start small, gather data, and expand.
For AI KPI management advice, contact us at hello@itinai.com. Stay updated on AI insights via our Telegram channel or Twitter.
Explore AI Solutions for Sales and Customer Engagement
Discover how AI can transform your business processes at itinai.com.
























