
The Future of Language Models: UltraMem
Revolutionizing Efficiency in AI
Large Language Models (LLMs) have transformed natural language processing but are often held back by high computational requirements. Although boosting model size enhances performance, it can lead to significant resource constraints in real-time applications.
Key Challenges and Solutions
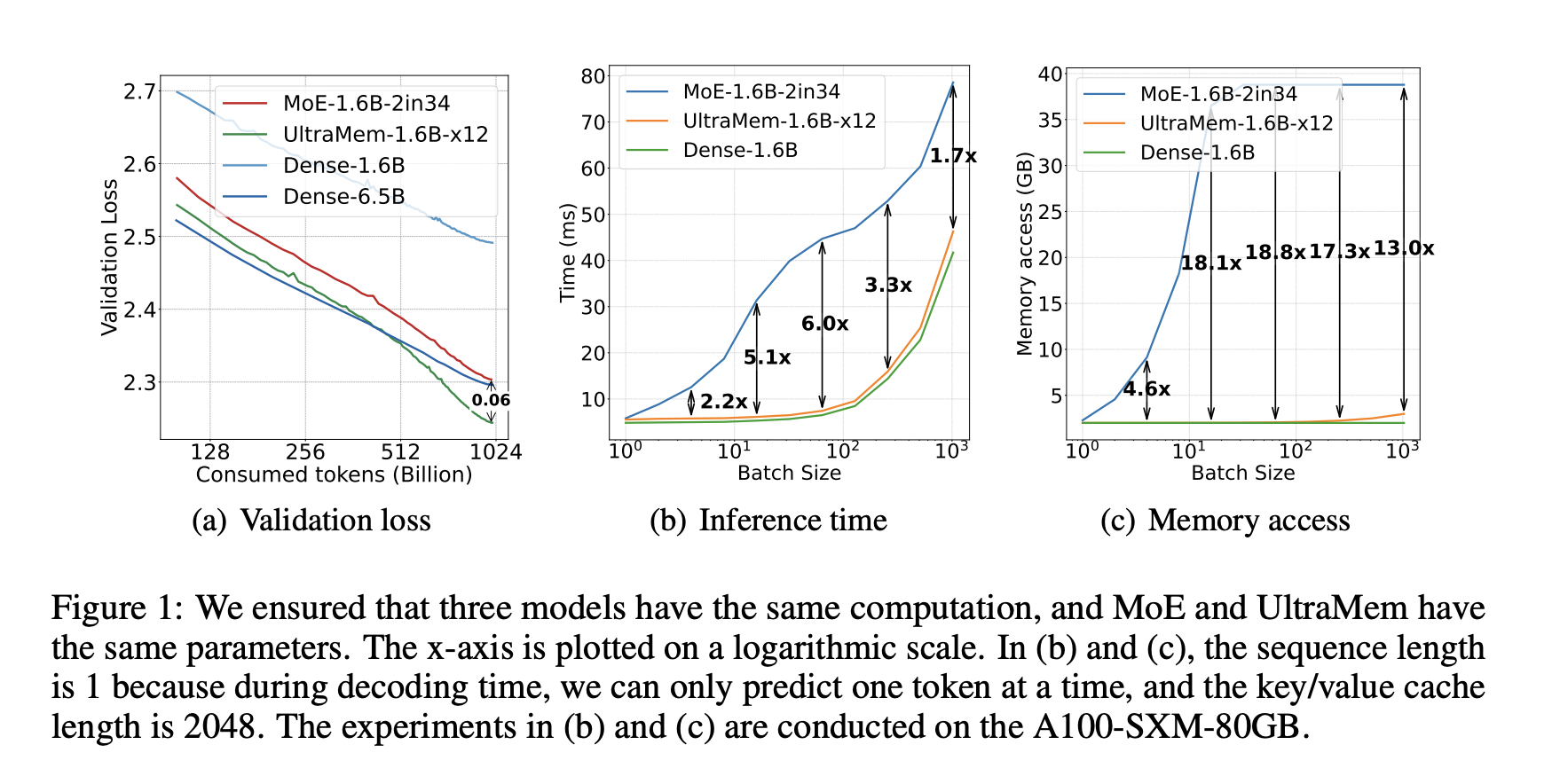
One solution, MoE (Mixture of Experts), improves training efficiency but slows down inference times due to increased memory demands. Another approach, Product Key Memory (PKM), offers consistent memory access with fewer embeddings but presents lower performance compared to MoE. For instance, MoE models can be 2 to 6 times slower than dense models during inference, even with 12 times the parameters.
Innovative Approaches to Efficiency
To tackle these challenges, researchers are enhancing MoE’s gating functions and expert selection strategies. New methods include:
- Slicing experts into smaller segments to optimize resource use.
- Using PKM with minimal expert configurations for improved access.
- Employing tensor decomposition techniques to reduce model size without sacrificing quality.
UltraMem: A Game-Changer
ByteDance’s team has developed UltraMem, an innovative architecture that significantly enhances memory usage in language models. Building on PKM, UltraMem introduces ultra-sparse memory layers, boosting computational efficiency and reducing latency.
Performance Highlights
UltraMem achieves:
- Up to 6 times faster inference speed than MoE models under standard conditions.
- Comparable efficiency to dense models with significantly fewer resources.
- Stable inference times even as model parameters grow.
Architectural Innovations
UltraMem features a Pre-LayerNorm Transformer design with multiple smaller memory layers, addressing issues of value retrieval and computational balance during training. The skip-layer structure optimizes memory operations, ensuring enhanced performance.
Conclusion
UltraMem represents a major advancement in LLM architecture, proving to be faster and more efficient than existing models. It is a strong foundation for creating powerful, resource-efficient language models that can transform the field of NLP.
Explore Further
Check out the Paper for in-depth research insights. Follow us on Twitter and join our 75k+ ML SubReddit for community engagement.
Enhance Your Business with AI
Stay competitive by leveraging UltraMem for your organization:
- Identify Automation Opportunities: Pinpoint areas in customer interaction that can benefit from AI.
- Define KPIs: Establish measurable impacts of AI on business outcomes.
- Select an AI Solution: Choose customizable tools that fit your needs.
- Implement Gradually: Test with a pilot program, gather data, and scale thoughtfully.
Connect with Us
For AI KPI management advice, email us at hello@itinai.com. Stay updated on AI insights via our Telegram and @Twitter.

























