
Understanding Test-Time Scaling (TTS)
Test-Time Scaling (TTS) is a technique that improves the performance of large language models (LLMs) by using extra computing power during the inference phase. However, there hasn’t been enough research on how different factors like policy models, Process Reward Models (PRMs), and task difficulty affect TTS. This limits our ability to apply TTS effectively.
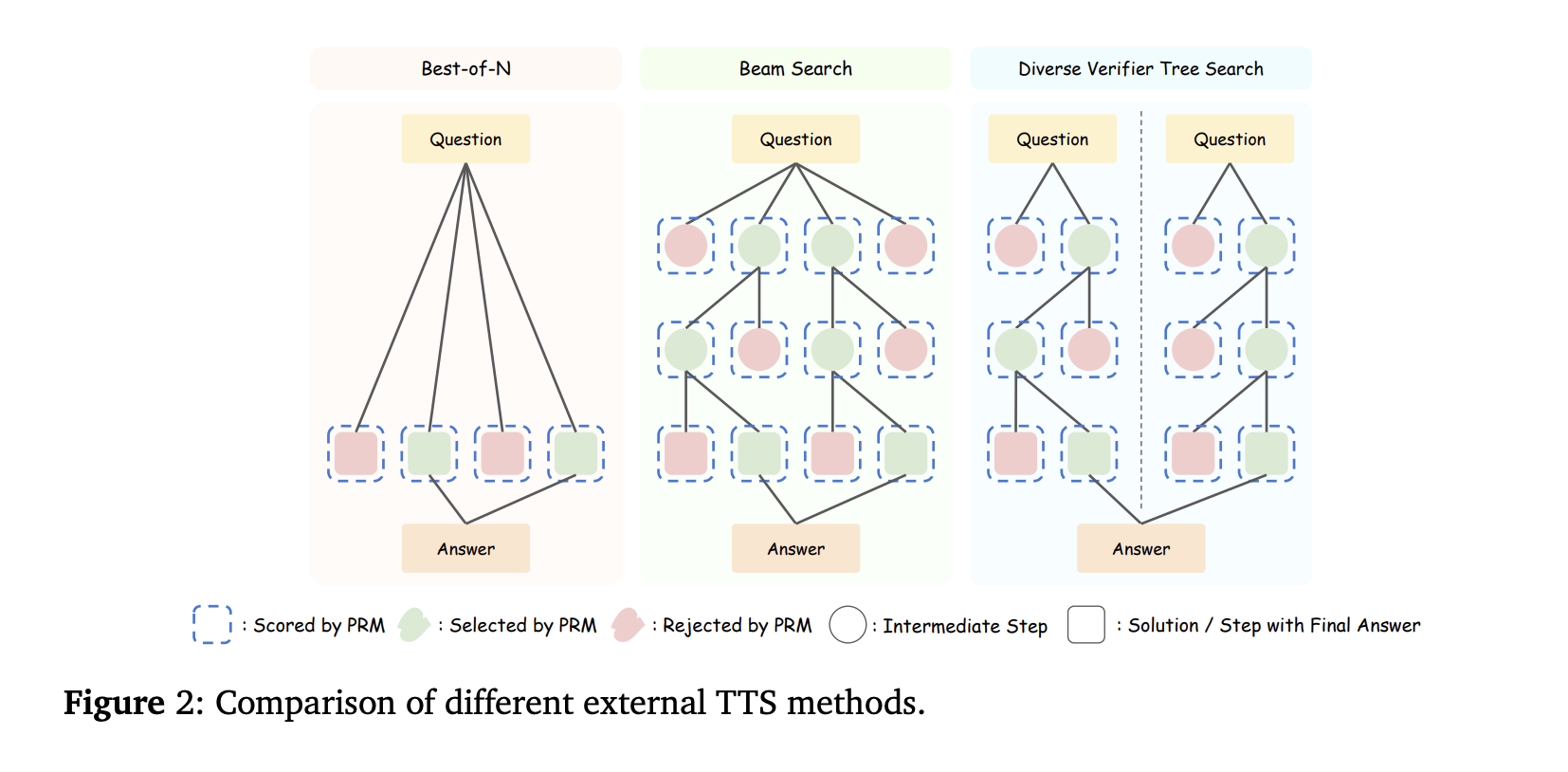
Types of TTS
TTS can be divided into two categories:
- Internal TTS: Improves reasoning by using detailed Chain-of-Thought (CoT) processes.
- External TTS: Boosts performance through sampling or search methods with fixed models.
The main challenge with External TTS is how to allocate computational resources efficiently for different tasks.
Research Findings on TTS
Previous studies have examined various strategies to enhance LLM performance, such as:
- Majority voting
- Search-based methods
- Self-refinement techniques
PRMs are found to perform better than Output Reward Models (ORMs) in refining outputs. New advancements in PRMs involve smarter data collection and ranking techniques to enhance mathematical reasoning.
Current Tools and Benchmarks
Tools like ProcessBench and PRMBench have been created to benchmark and assess the effectiveness of PRMs. This evolution highlights the need for more systematic research to optimize LLM performance across various tasks.
The Impact of Models and Complexity
Researchers from notable institutions have studied how policy models, PRMs, and problem complexity affect TTS using extensive tasks like MATH-500 and AIME24. Their work shows that:
- Smaller models can outperform larger ones with better efficiency.
- Reward-aware TTS is crucial for effective scaling.
- Strategic computation significantly boosts reasoning abilities across different architectures.
Optimizing Computational Resources
Compute-optimal TTS makes efficient use of computational resources for each problem. The study reveals that:
- On-policy PRMs provide more precise rewards than offline models.
- Rewards impact TTS performance significantly.
- Problem difficulty is better judged with absolute thresholds for effective scaling.
Conclusion and Future Directions
Findings indicate that smaller models can surpass larger ones by utilizing optimized TTS, highlighting a shift toward more efficient supervision methods. Future research should focus on enhancing these methods and exploring TTS applications in areas like coding and chemistry.
Practical Solutions and Business Value
To leverage AI effectively, consider these steps:
- Identify Automation Opportunities: Find areas in customer interactions that could benefit from AI.
- Define KPIs: Establish measurable goals for your AI initiatives.
- Select an AI Solution: Choose tools that fit your specific needs and can be customized.
- Implement Gradually: Start small, gather insights, and expand usage wisely.
For specific advice on AI KPI management, reach out to us at hello@itinai.com. Stay updated on AI insights via our Telegram or follow us on @itinaicom.
Explore Further
Discover how AI can transform your sales processes by visiting itinai.com.


























