
Reinforcement Learning for Large Language Models
Challenges with Traditional Methods
Traditional reinforcement learning (RL) for large language models (LLMs) uses outcome-based rewards, giving feedback only on the final results. This approach creates difficulties for tasks that require multi-step reasoning, such as math problem-solving and programming. The lack of intermediate feedback makes it hard to assign credit for individual steps in the process.
Limitations of Current Approaches
Current methods, like process reward models (PRMs), provide detailed rewards for each step but require expensive human annotations. Additionally, static reward functions can lead to overoptimization and reward hacking, which hampers the model’s overall performance. These challenges limit RL’s effectiveness, scalability, and use in LLMs, highlighting the need for new solutions that combine dense rewards without high costs or manual work.
Proposed Solution: Implicit Process Reward Model
A team of researchers has developed a new RL framework that eliminates the need for explicit annotations. They introduce the Implicit Process Reward Model (Implicit PRM), which generates rewards for individual tokens without requiring human guidance. This allows for continuous improvement of the reward model while avoiding issues like overoptimization.
Key Features of the New Framework
- Token-Level Rewards: Rewards are calculated without manual data, providing immediate feedback from existing outcome labels.
- Online Learning: The model updates the reward function in real-time, preventing overoptimization and reward manipulation.
- Efficient Training: The framework integrates with various RL methods, such as REINFORCE and PPO, making it adaptable and scalable.
Improved Performance and Efficiency
This new RL system has shown significant improvements in sample efficiency and reasoning abilities. Compared to traditional outcome-based methods, it offers:
- A 2.5× increase in sample efficiency.
- A 6.9% improvement in solving mathematical problems.
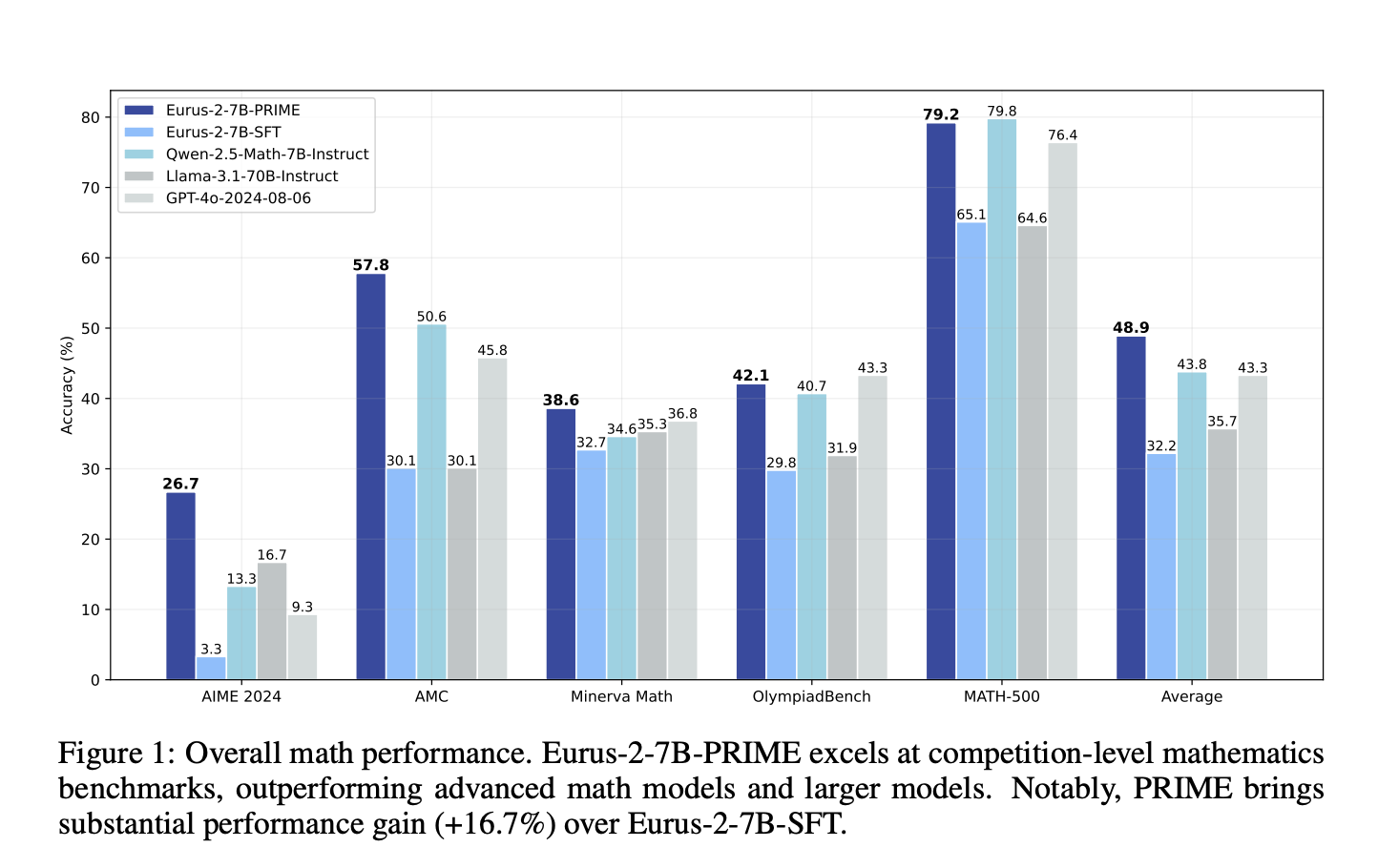
It outperforms existing models, like Qwen2.5-Math-7B-Instruct, especially in challenging tasks, all while using less training data.
Benefits of the Reinforcement Learning Approach
This RL framework provides a cost-effective and efficient way to train LLMs. By removing the need for step-level annotations and enhancing sample efficiency, stability, and performance, it addresses long-standing challenges in RL. This advancement optimizes AI’s reasoning capabilities, making it highly valuable for mathematical and programming applications.
Get Involved!
Explore the full research here and visit our GitHub Page. Follow us on Twitter, join our Telegram Channel, and connect with our LinkedIn Group. Join our community of over 75k on ML SubReddit.
Transform Your Business with AI
Enhance your company’s performance with the PRIME framework:
- Identify Automation Opportunities: Find areas in customer interactions that can benefit from AI.
- Define KPIs: Set measurable objectives for your AI projects.
- Select an AI Solution: Choose tools that fit your needs and can be customized.
- Implement Gradually: Start with a pilot, collect data, and expand AI use strategically.
For advice on managing AI KPIs, reach us at hello@itinai.com. For ongoing AI insights, follow us on Telegram or @itinaicom.
Revolutionize Your Sales and Customer Engagement
Explore innovative AI solutions at itinai.com.























