
Understanding Multimodal AI with MILS
What are Large Language Models (LLMs)?
LLMs are mainly used for text tasks, which limits their ability to work with images, videos, and audio. Traditional multimodal systems require a lot of labeled data and are not flexible for new tasks.
The Challenge
The goal is to enable LLMs to handle multimodal tasks without needing specific training or curated data. This would greatly expand their use in various fields.
Current Limitations
Existing multimodal AI systems, like CLIP and diffusion models, rely on extensive training and cannot easily adapt to new tasks. They struggle with three main issues:
– Dependence on large labeled datasets.
– Inability to generalize beyond their training data.
– Limited flexibility due to their reliance on gradient-based methods.
Introducing MILS
Meta has developed MILS (Multimodal Iterative LLM Solver), a framework that enhances LLMs for multimodal tasks without extra training. It uses a two-step process:
1. **GENERATOR**: An LLM that creates potential solutions (like captions for images).
2. **SCORER**: A pre-trained model that evaluates these solutions based on relevance and coherence.
This back-and-forth process allows MILS to improve its outputs in real-time, making it adaptable across text, images, videos, and audio.
How MILS Works
MILS operates without tuning pre-trained models. It has been applied successfully in various tasks:
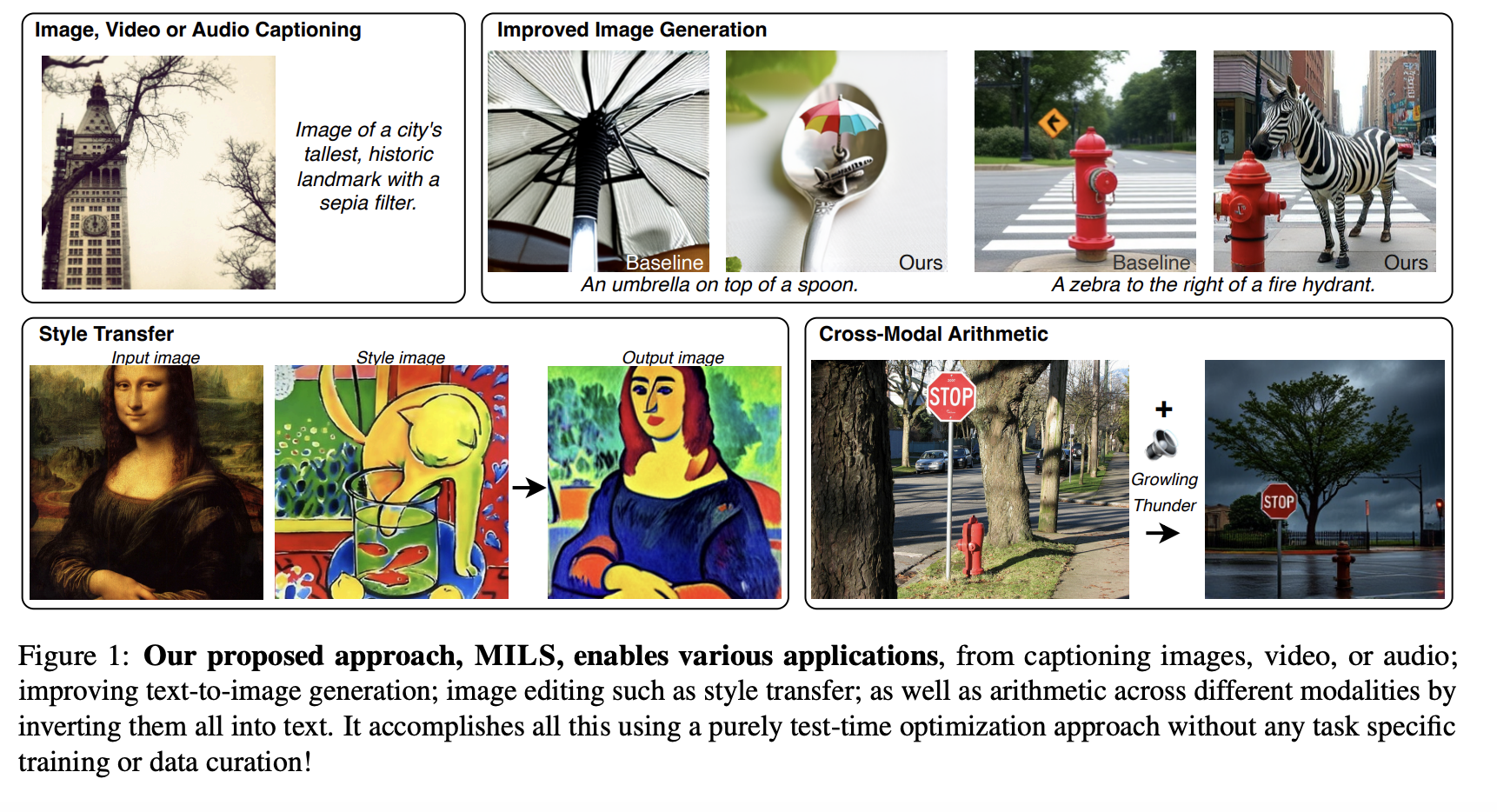
– **Image Captioning**: Uses Llama 3.1 8B as the GENERATOR and CLIP for scoring to produce accurate captions.
– **Video and Audio Captioning**: Similar iterative processes are used for video frames and audio descriptions.
– **Text-to-Image Generation**: Optimizes prompts for better image quality.
– **Style Transfer**: Generates prompts for visually consistent transformations.
– **Cross-Modal Arithmetic**: Combines different types of data into a single representation.
Performance and Benefits
MILS shows strong zero-shot performance, outperforming previous models in:
– **Image Captioning**: Produces more accurate and informative captions.
– **Video and Audio Captioning**: Surpasses models trained on large datasets.
– **Text-to-Image Generation**: Improves image quality and is preferred by users.
– **Style Transfer**: Learns optimal prompts for better results.
MILS represents a significant advancement in multimodal AI, allowing LLMs to generate and process various content types without the need for training.
Why Choose MILS?
MILS offers a new way to use AI effectively:
– **No Training Needed**: Quickly adapt LLMs for multimodal tasks.
– **Iterative Optimization**: Continuously improve outputs with real-time feedback.
– **Scalable Solutions**: Easily implement across different applications.
Get Involved
Explore the potential of MILS for your business. Identify automation opportunities, define measurable KPIs, select suitable AI solutions, and implement them gradually.
For more insights, connect with us at hello@itinai.com, and follow us on our social media channels.
Transform Your Business with AI
Discover how AI can enhance your sales processes and customer engagement at itinai.com.
























