
AI Safeguards Against Exploitation
Large language models (LLMs) are widely used but can be vulnerable to misuse. A major issue is the emergence of universal jailbreaks—methods that bypass security measures, granting access to restricted information. This misuse can lead to harmful actions, such as creating illegal substances or breaking cybersecurity protocols. As AI develops, so do the ways it can be exploited, making it crucial to implement effective safeguards that ensure security while remaining user-friendly.
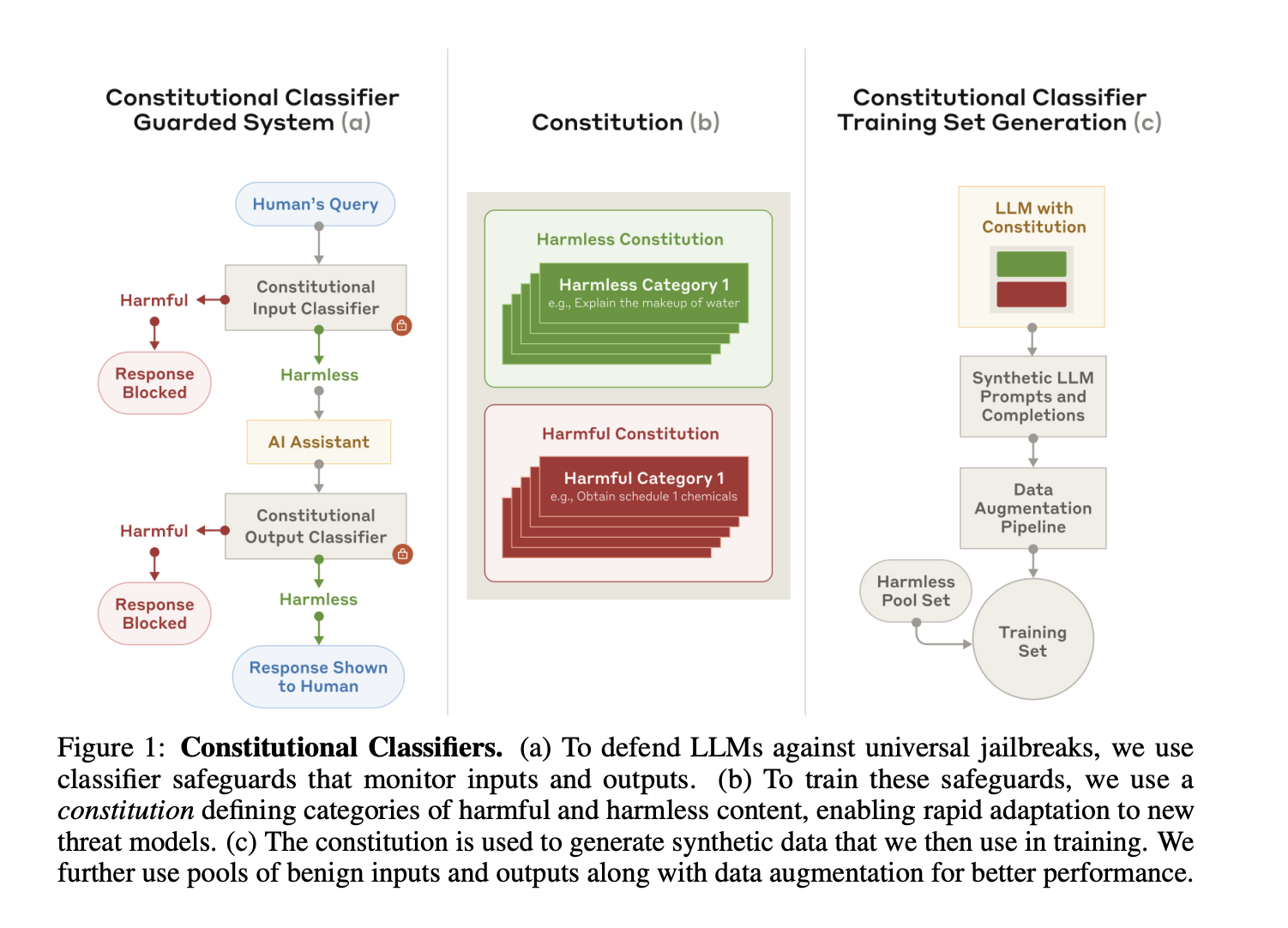
Introducing Constitutional Classifiers
To address these concerns, Anthropic researchers have developed Constitutional Classifiers. This framework enhances LLM safety by utilizing synthetic data based on clear constitutional principles. By defining what content is restricted or allowed, it creates a flexible system ready to tackle new threats.
Key Benefits of Constitutional Classifiers:
- Prevention Against Jailbreaks: Classifiers are trained to recognize and block harmful content, making them better at stopping jailbreak attempts.
- Real-World Usability: The system has a manageable 23.7% inference overhead, ensuring it can be effectively used in practice.
- Adaptability: The constitutional rules can be updated, allowing the system to respond to new security challenges.
How It Works
The classifiers operate at both stages:
- The input classifier screens prompts to block harmful queries.
- The output classifier reviews responses in real-time, allowing for immediate intervention if needed.
Test Results and Effectiveness
Anthropic tested the system for over 3,000 hours with 405 participants, including security and AI experts. The results were promising:
- No universal jailbreaks were found that could consistently bypass the safeguards.
- The system effectively blocked 95% of jailbreak attempts, a significant increase from the 14% refusal rate seen in unprotected models.
- Real-world usage saw only a 0.38% rise in refusals, indicating minimal unnecessary restrictions.
Conclusion
Anthropic’s Constitutional Classifiers provide a practical approach to enhancing AI safety. By aligning safeguards with specific constitutional principles, the system offers a scalable method to manage security risks without severely limiting legitimate use. Ongoing updates will be essential as adversarial techniques grow, but this framework shows promise in significantly reducing risks while maintaining functionality.
Explore AI Opportunities
If you want to enhance your business with AI, consider the following steps:
- Identify Automation Opportunities: Find key areas in customer interactions that can benefit from AI.
- Define KPIs: Ensure your AI initiatives have measurable impacts.
- Select an AI Solution: Choose tools that fit your needs.
- Implement Gradually: Start small, gather data, and scale up cautiously.
For AI KPI management advice, connect with us at hello@itinai.com. Stay updated on AI insights via our Telegram or follow us on @itinaicom.
Discover how AI can improve your sales and customer engagement by visiting itinai.com.


























