
Understanding AI Learning Techniques: Memorization vs. Generalization
Importance of Adaptation in AI Systems
Modern AI systems often use techniques like Supervised Fine-Tuning (SFT) and Reinforcement Learning (RL) to improve their performance on specific tasks. However, a key question is whether these methods help AI models remember training data or adapt successfully to new situations. This understanding is crucial for creating strong AI systems that can manage real-world challenges.
Challenges with SFT and RL
Research suggests that SFT may lead to overfitting, causing models to become less flexible when faced with new tasks. For example, an SFT-tuned model might do well with arithmetic problems using specific values but struggle if the rules change. On the other hand, RL can foster adaptability, but it may also reinforce limited strategies depending on how it is applied. Current evaluations often mix memorization with actual generalization, leaving users unsure of the best approach.
New Research Insights
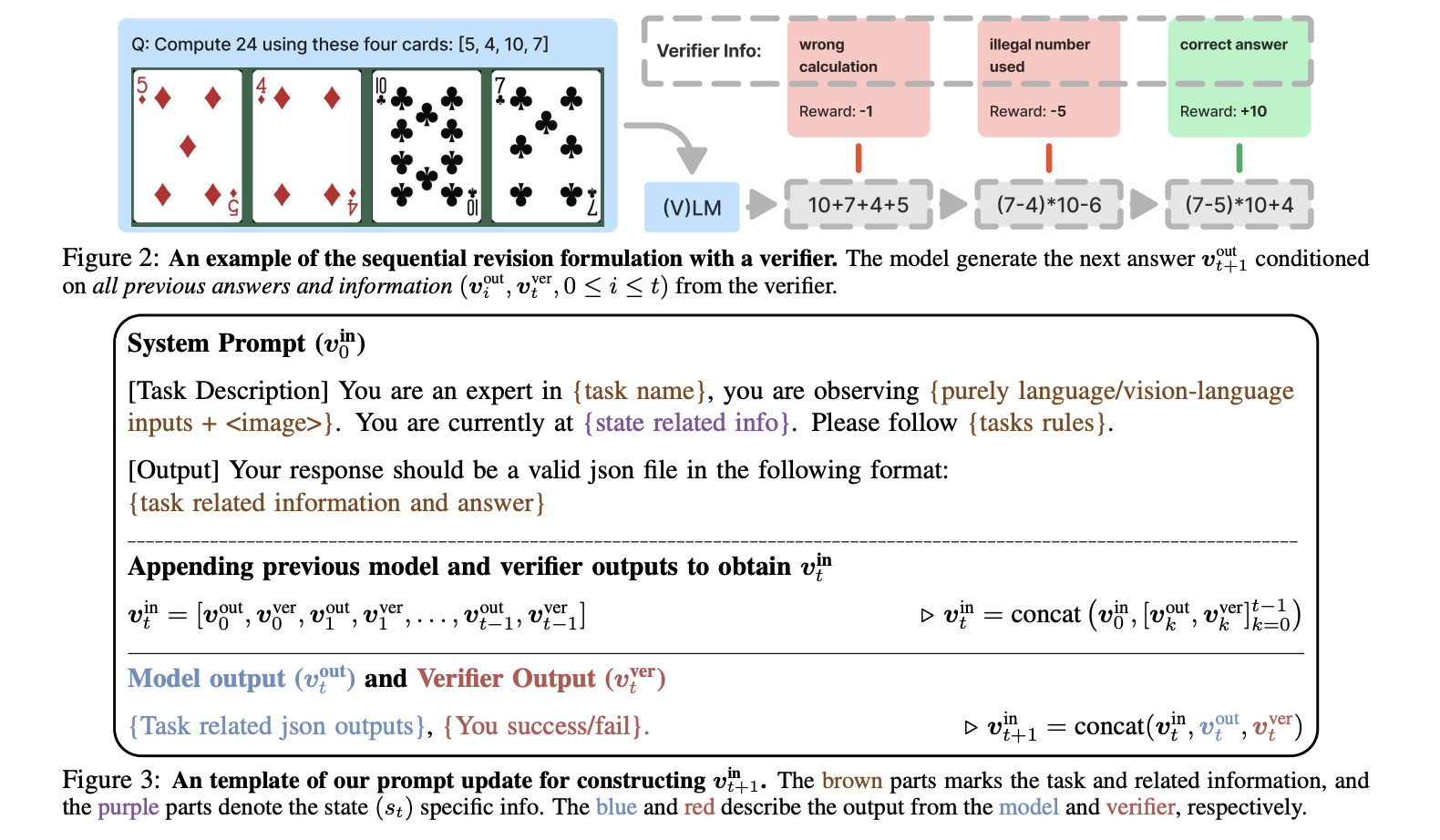
A recent study from researchers at HKU, UC Berkeley, Google DeepMind, and NYU compares SFT and RL to see how they influence a model’s adaptability to new challenges. They propose controlled testing to differentiate between memorization and generalization, using two tasks:
– **GeneralPoints**: Involves creating equations to reach 24 using playing cards with varying rules.
– **V-IRL**: Focuses on navigating to a target using visual cues, with changes in command types and environments.
Key Findings from the Study
The research uses the Llama-3.2-Vision-11B model, first applying SFT, then RL. They found:
– **SFT Tends to Memorize**: SFT encourages models to replicate exact answers from training data, leading to poor performance when faced with new scenarios.
– **RL Promotes Generalization**: RL enhances a model’s ability to adapt and understand task structures, thus improving performance on unseen challenges.
The study also highlights that RL benefits from multiple attempts during training, leading to better adaptability.
Performance Comparison
The results show that RL consistently outperforms SFT in various tasks:
– **Rule-Based Tasks**: RL improved accuracy by +3.5% and +11.0%, while SFT dropped by -8.1% and -79.5%.
– **Visual Tasks**: RL showed gains of +17.6% and +61.1%, while SFT decreased by -9.9% and -5.6%.
Conclusion and Practical Implications
The study highlights a trade-off: SFT is good for fitting training data but struggles with new challenges, while RL focuses on adaptability. For practitioners, it’s best to use SFT initially, followed by RL, but avoid relying too much on SFT to prevent locking in memorized patterns.
Ready to help your business thrive with AI? Here are some steps to consider:
– **Identify Opportunities**: Find areas where AI can improve customer interactions.
– **Set Clear Goals**: Define KPIs to measure the impact of your AI efforts.
– **Choose the Right Tools**: Select AI solutions that fit your business needs.
– **Implement Gradually**: Begin with pilot projects, gather data, and expand thoughtfully.
For more insights on leveraging AI, connect with us at hello@itinai.com or follow us on Twitter and join our Telegram channel.
Discover how AI can transform your business processes by visiting itinai.com.



























