
Understanding Multimodal Large Language Models (MLLMs)
Multimodal large language models (MLLMs) are a promising step towards achieving artificial general intelligence. They combine different types of sensory information into one system. However, they struggle with basic vision tasks, performing much worse than humans. Key challenges include:
- Object Recognition: Identifying objects accurately.
- Localization: Determining where objects are located.
- Motion Recall: Remembering movements over time.
Despite ongoing research, reaching human-level visual understanding is still a challenge. Developing systems that can interpret and reason across various sensory inputs with human-like accuracy remains complex.
Current Research Approaches
Researchers are exploring different methods to improve visual understanding in MLLMs. These include:
- Combining Technologies: Using vision encoders, language models, and connectors to perform complex tasks like image descriptions and visual queries.
- Video Processing: Enhancing MLLMs to handle sequential visuals and understand changes over time.
However, challenges persist in detailed visual tasks, leading to two main strategies:
- Pixel-to-Sequence (P2S): A method for processing visual data.
- Pixel-to-Embedding (P2E): An approach for embedding visual information.
Introducing InternVideo2.5
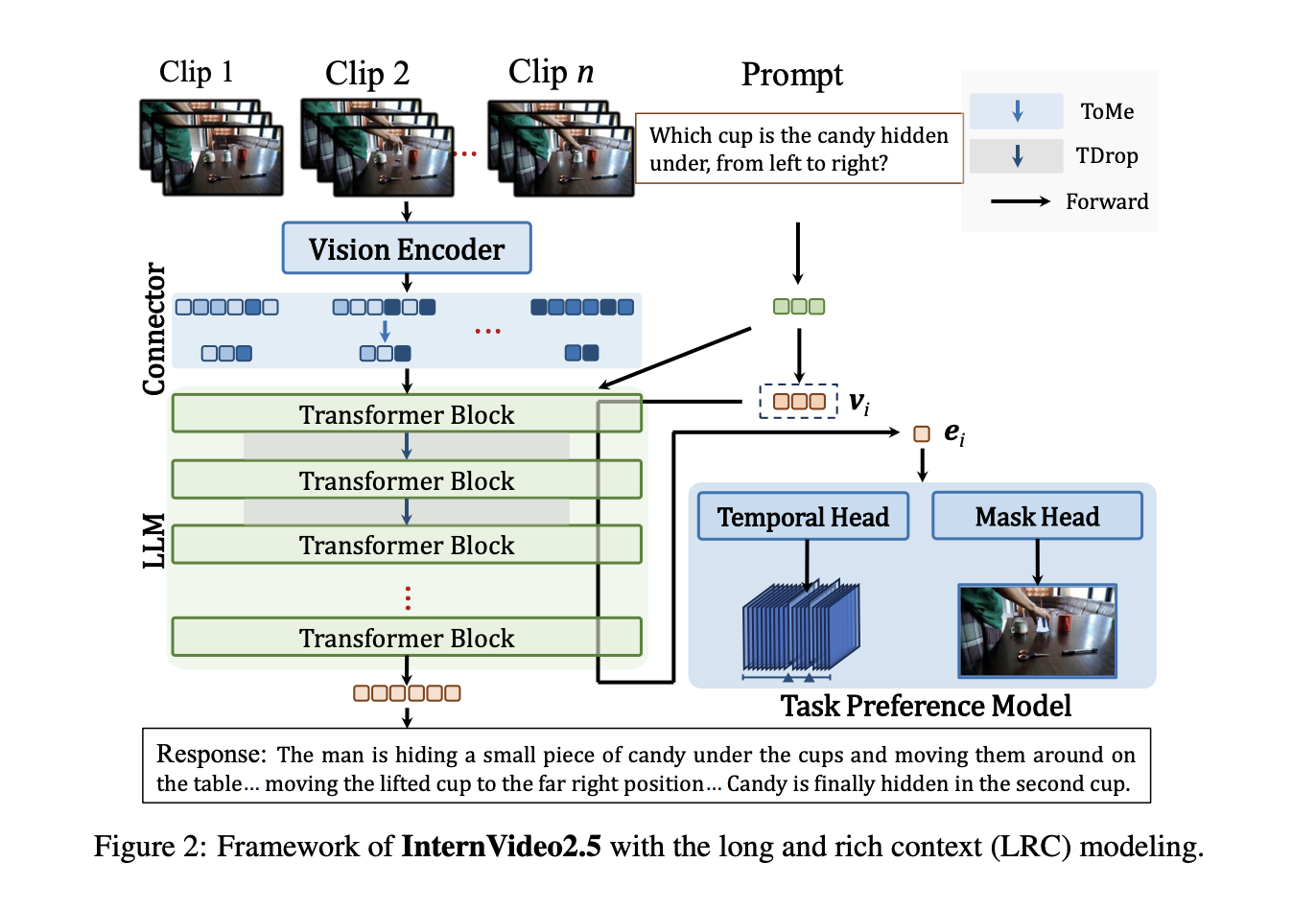
Researchers from Shanghai AI Laboratory, Nanjing University, and Shenzhen Institutes of Advanced Technology have developed InternVideo2.5. This new model enhances video MLLM capabilities by:
- Long and Rich Context (LRC) Modeling: Improving the understanding of detailed video content and complex time sequences.
- Integrating Annotations: Using direct preference optimization to incorporate detailed visual task annotations.
- Adaptive Hierarchical Token Compression: Creating efficient representations of spatiotemporal data.
Key Features of InternVideo2.5
The architecture of InternVideo2.5 includes:
- Dynamic Video Sampling: Processing between 64 to 512 frames, compressing each 8-frame clip into 128 tokens.
- Advanced Components: Utilizing a Temporal Head based on CG-DETR and a Mask Head with SAM2’s pre-trained weights.
- Optimized Processing: Implementing two-layer MLPs for better positioning and encoding of spatial inputs.
Performance Improvements
InternVideo2.5 shows significant advancements in video understanding tasks:
- Enhanced Accuracy: Over 3 points improvement on MVBench and Perception Test for short video predictions.
- Superior Recall: Demonstrated better memory capabilities in complex tasks.
Conclusion
InternVideo2.5 represents a major step forward in video MLLM technology, focusing on:
- Improved Visual Capabilities: Enhancements in object tracking and understanding.
- Future Research Opportunities: Addressing high computational costs and extending context processing techniques.
For more details, check out the Paper and GitHub. Follow us on Twitter, join our Telegram Channel, and connect with our LinkedIn Group. Also, join our 70k+ ML SubReddit.
Transform Your Business with AI
To stay competitive, consider using InternVideo2.5 in your operations:
- Identify Automation Opportunities: Find key areas in customer interactions that can benefit from AI.
- Define KPIs: Ensure your AI projects have measurable impacts on your business.
- Select an AI Solution: Choose tools that fit your needs and allow customization.
- Implement Gradually: Start with a pilot project, gather data, and expand AI use wisely.
For AI KPI management advice, connect with us at hello@itinai.com. For ongoing insights, follow us on Telegram or Twitter.
Explore how AI can enhance your sales processes and customer engagement at itinai.com.


























