
Advancements in Natural Language Processing
Recent developments in large language models (LLMs) have improved natural language processing (NLP) by enabling better understanding of context, code generation, and reasoning. Yet, one major challenge remains: the limited size of the context window. Most LLMs can only manage around 128K tokens, which restricts their ability to analyze long documents or debug extensive codebases. This often leads to complex solutions like text chunking. What is needed are models that efficiently extend context lengths without sacrificing performance.
Qwen AI’s Latest Innovations
Qwen AI has launched two new models: Qwen2.5-7B-Instruct-1M and Qwen2.5-14B-Instruct-1M, both capable of handling context lengths up to 1 million tokens. Developed by Alibaba Group’s Qwen team, these models come with an open-source inference framework specifically designed for long contexts. This allows developers and researchers to process larger datasets seamlessly, providing a direct solution for applications needing extensive context handling. The models also enhance processing speed with advanced attention mechanisms and optimization techniques.
Key Features and Advantages
The Qwen2.5-1M series uses a Transformer-based architecture and incorporates significant features like:
- Grouped Query Attention (GQA)
- Rotary Positional Embeddings (RoPE)
- RMSNorm for stability over long contexts
Training on both natural and synthetic datasets improves the model’s capacity to handle long-range dependencies. Efficient inference is supported through sparse attention methods like Dual Chunk Attention (DCA). Progressive pre-training invests in efficiency by gradually increasing context lengths, while full compatibility with the vLLM open-source inference framework eases integration for developers.
Performance Insights
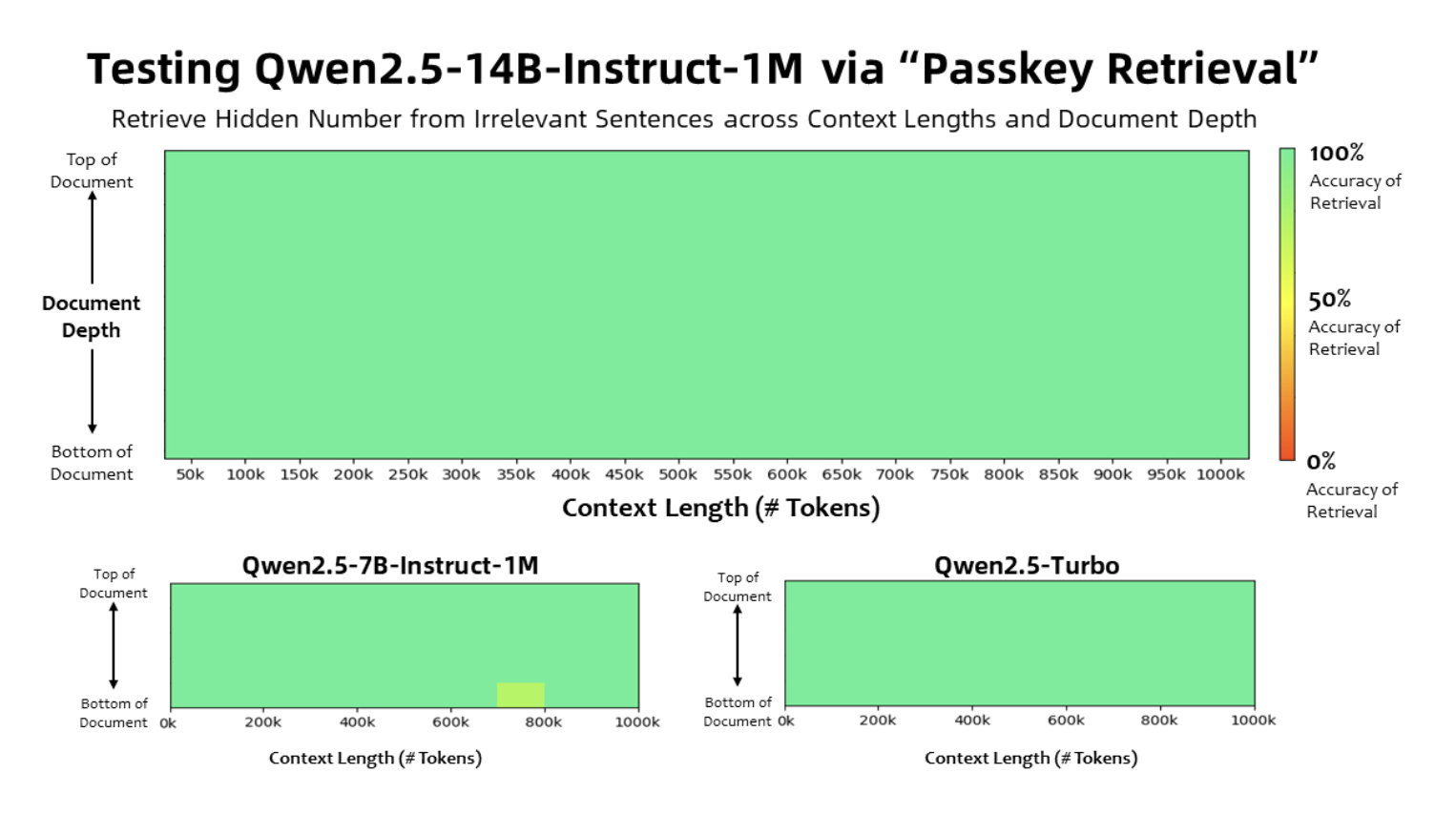
Benchmark tests highlight the Qwen2.5-1M models’ capabilities. In the Passkey Retrieval Test, the 7B and 14B variants successfully retrieved data from 1 million tokens. In comparison benchmarks like RULER and Needle in a Haystack (NIAH), the 14B model outperformed others such as GPT-4o-mini and Llama-3. Utilizing sparse attention techniques led to faster inference times, achieving improvements of up to 6.7x on Nvidia H20 GPUs. These results emphasize the models’ efficiency and high performance for real-world applications requiring extensive context processing.
Conclusion
The Qwen2.5-1M series effectively addresses critical NLP limitations by significantly broadening context lengths while ensuring efficiency and accessibility. By overcoming long-standing constraints of LLMs, these models expand opportunities for applications like large dataset analysis and complete code repository processing. Thanks to innovations in sparse attention, kernel optimization, and long-context pre-training, Qwen2.5-1M serves as a practical tool for complex, context-heavy tasks.
Taking Advantage of AI
If you want to elevate your business with AI, leveraging Qwen AI’s new models is essential. Here’s how to redefine your work with AI:
- Identify Automation Opportunities: Find key customer interactions that can benefit from AI.
- Define KPIs: Ensure your AI efforts have measurable impacts on your business.
- Select an AI Solution: Choose tools that meet your requirements and offer customization.
- Implement Gradually: Start with a pilot program to gather data and expand AI implementation wisely.
For advice on AI KPI management, contact us at hello@itinai.com. To stay updated on leveraging AI, follow us on Twitter and join our Telegram channel.























