
Aligning Large Language Models with Human Values
Importance of Alignment
As large language models (LLMs) play a bigger role in society, aligning them with human values is crucial. A challenge arises when we cannot change the model’s settings directly. Instead, we can adjust the input prompts to help the model produce better outputs. However, this method lacks a strong theoretical basis, raising questions about its effectiveness compared to direct adjustments of the model.
Current Alignment Methods
Current alignment techniques, like reinforcement learning from human feedback (RLHF), focus on fine-tuning model parameters. While effective, these methods require significant resources, making them impractical for fixed models. New methods, such as direct preference optimization, also depend on parameter updates, limiting their use. Recently, prompt optimization has emerged as a potential alternative, but its theoretical foundation is still unclear.
Introducing Align-Pro
Researchers from the University of Central Florida, the University of Maryland, and Purdue University have developed Align-Pro, a prompt optimization framework that aligns LLMs without changing their parameters. This framework includes:
- Supervised Fine-Tuning (SFT): Fine-tunes pre-trained models using human-generated data.
- Reward Learning: Trains a model to evaluate outputs based on expert feedback.
- Reinforcement Learning (RL): Maximizes alignment through iterative fine-tuning.
Align-Pro uses a smaller, trainable model to adjust prompts, ensuring efficient alignment without altering the larger models.
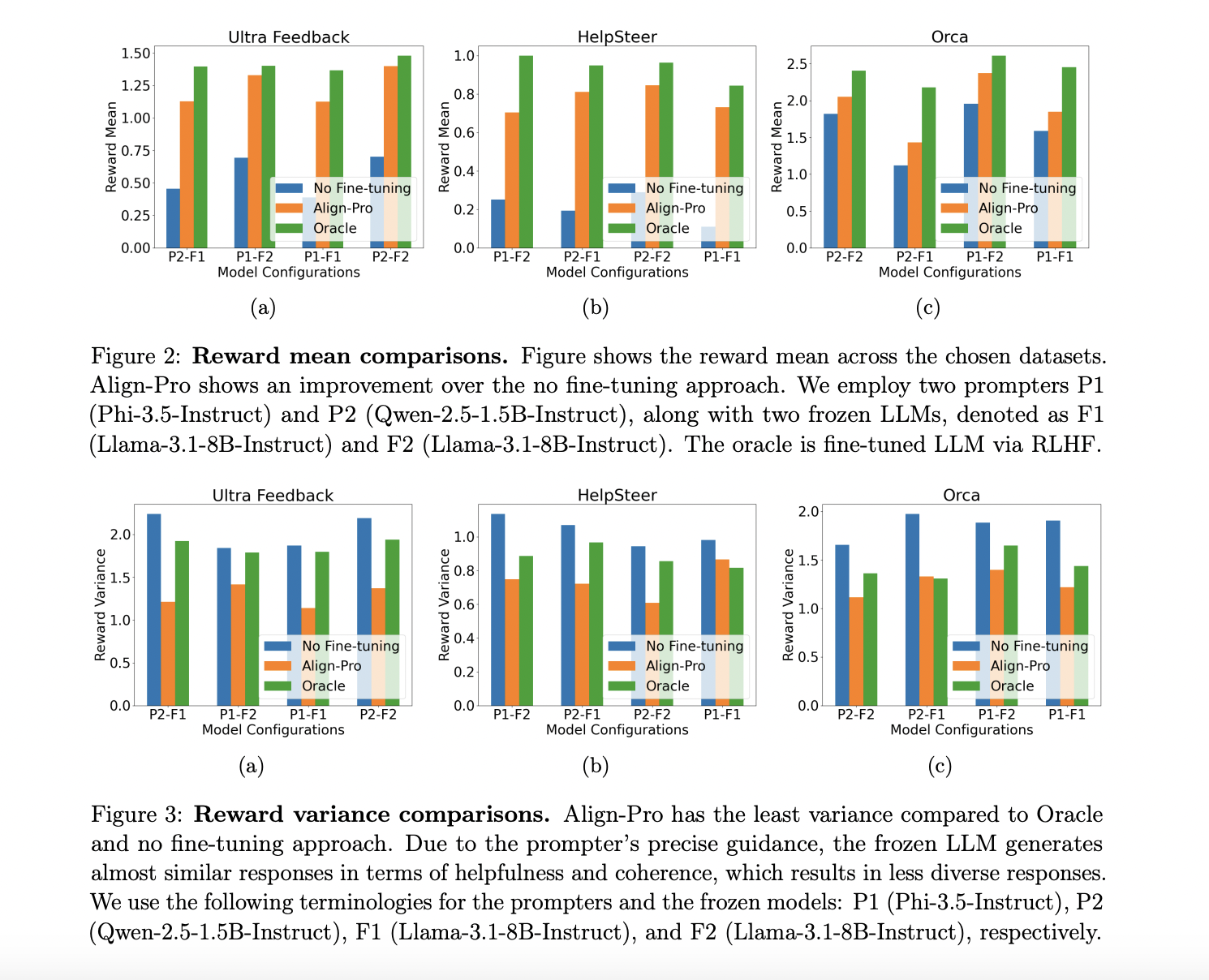
Experimental Results
Experiments were conducted using two prompter models and two frozen models. The framework was tested in three configurations: no fine-tuning, Align-Pro with a fine-tuned prompter, and RLHF with a fine-tuned model. Results showed that Align-Pro consistently outperformed the baseline, achieving:
- Higher mean rewards
- Lower reward variance
- Win rates up to 67%
This indicates that Align-Pro can efficiently optimize prompts without needing to fine-tune the LLMs directly.
Conclusion and Future Potential
The Align-Pro framework offers a cost-effective way to enhance LLM alignment while minimizing computational costs. Its success across various datasets suggests significant potential for future AI research. Further advancements may explore prompt robustness, sequential designs, and theoretical improvements for better alignment.
Get Involved
Check out the paper for more details. Follow us on Twitter, join our Telegram Channel, and participate in our LinkedIn Group. Don’t forget to join our 70k+ ML SubReddit!
Leverage AI for Your Business
Stay competitive and evolve your company with AI solutions like Align-Pro. Here’s how:
- Identify Automation Opportunities: Find key customer interactions that can benefit from AI.
- Define KPIs: Ensure measurable impacts from your AI initiatives.
- Select an AI Solution: Choose tools that fit your needs and allow customization.
- Implement Gradually: Start with a pilot project, gather data, and expand wisely.
For AI KPI management advice, contact us at hello@itinai.com. For ongoing insights, follow us on Telegram at t.me/itinainews or Twitter @itinaicom.
Discover how AI can transform your sales processes and customer engagement. Explore solutions at itinai.com.



























