
Challenges in Using Open Datasets for AI Training
Large language models (LLMs) need open datasets for training, but this comes with serious legal, technical, and ethical issues. The use of data can be complicated due to different copyright laws and changing regulations. There are no global standards or centralized databases to check the legal status of datasets, which makes it hard to know if data can be used safely. Additionally, many open datasets lack proper governance, putting contributors at risk and making it difficult to scale.
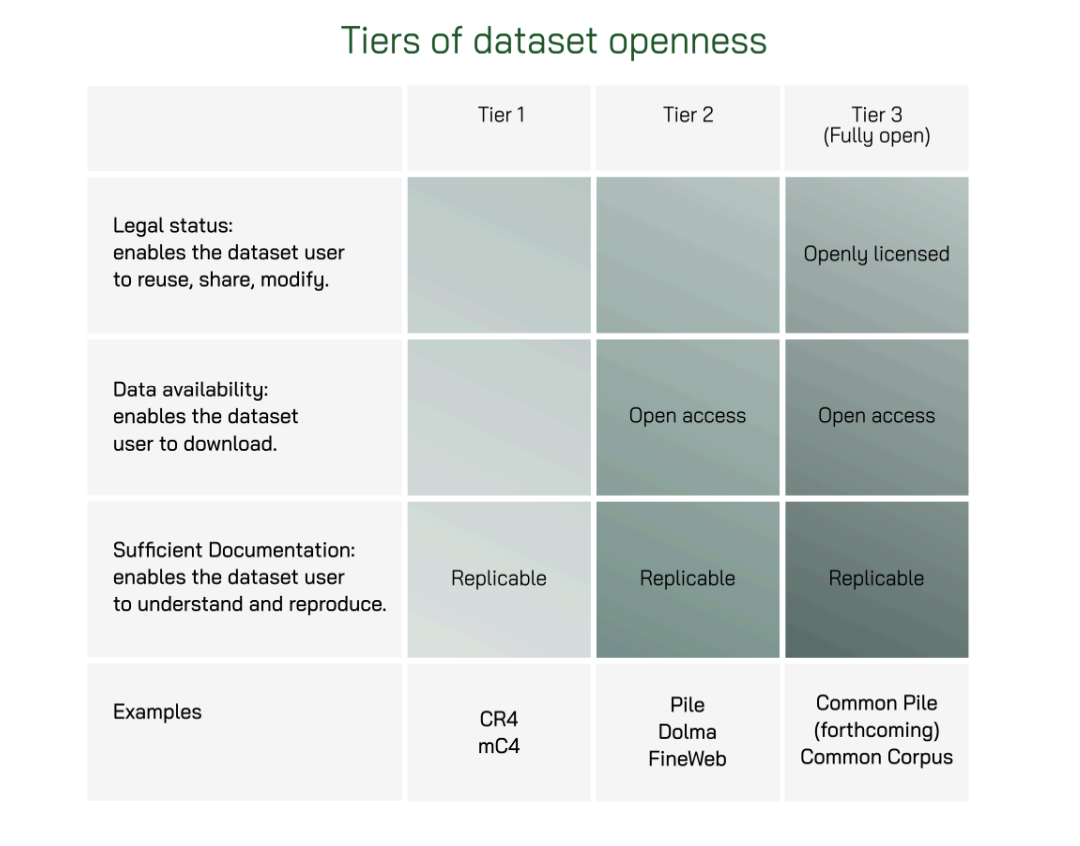
Current Limitations in Dataset Building
Current methods for creating open datasets face major challenges. They often rely on incomplete information, making it hard to verify copyright and comply with various laws. Accessing digitized public domain materials is tough because large projects limit usage. Volunteer projects often lack governance, exposing contributors to legal risks. This situation limits diversity in data representation and concentrates power among a few organizations, hindering progress in AI development.
Proposed Solutions for Better Data Management
To address issues in dataset management, researchers suggest a framework that uses openly licensed and public domain data for LLM training. This framework focuses on:
- Reliable Metadata: Ensuring accurate information about data sources.
- Digitization: Making physical records available in digital form.
- Collaboration: Working with various communities to curate and govern datasets.
- Diversity: Ensuring a variety of data sources to represent different viewpoints.
Practical Steps for Implementation
The framework includes practical steps for sourcing, processing, and governing datasets:
- Using tools to detect openly licensed content for high-quality data.
- Standardizing metadata for consistency.
- Encouraging community collaboration in dataset creation.
- Addressing biases and harmful content to build a robust training system.
Engaging with Communities for Sustainable Data
Researchers emphasize the importance of engaging underrepresented communities to create diverse datasets. They also call for clearer terms of use that are easy for machines to read. Sustainable funding models from tech companies and cultural institutions are suggested to support ongoing participation in the open data ecosystem.
Future Directions and Innovations
The researchers outline a clear plan to tackle the challenges of using non-licensed data for LLM training. Key initiatives include:
- Standardizing metadata.
- Enhancing the digitization process.
- Implementing responsible governance.
Get Involved and Stay Updated
Check out the research paper for more insights. All credit goes to the researchers involved. Follow us on Twitter, join our Telegram Channel, and connect with our LinkedIn Group. Don’t miss out on joining our 65k+ ML SubReddit.
Transform Your Business with AI
To stay competitive, consider how AI can enhance your operations:
- Identify Automation Opportunities: Find areas in customer interactions that could benefit from AI.
- Define KPIs: Set measurable goals for your AI initiatives.
- Select an AI Solution: Choose tools that fit your needs and allow for customization.
- Implement Gradually: Start small, gather data, and expand usage carefully.
For AI KPI management advice, reach out to us at hello@itinai.com. For ongoing insights into leveraging AI, follow us on Telegram t.me/itinainews or Twitter @itinaicom.
Discover how AI can transform your sales processes and customer engagement by exploring solutions at itinai.com.

























