
Understanding Vision-Language Models (VLMs)
Vision-language models (VLMs) are advanced AI systems that combine computer vision and natural language processing. They can analyze both images and text simultaneously, leading to practical applications in areas like medical imaging, automation, and digital content analysis. By connecting visual and textual data, VLMs are essential for multimodal intelligence research.
Challenges in VLM Safety
One major challenge in developing VLMs is ensuring the safety of their outputs. Visual inputs may contain harmful information that can bypass model defenses, leading to unsafe or inappropriate responses. While text-based safety measures are improving, visual data remains vulnerable because it is continuous and harder to evaluate effectively.
Current Safety Approaches
Current methods for ensuring VLM safety include:
- Fine-tuning: This involves training models with extensive data and human feedback, which can be resource-intensive and may reduce overall model performance.
- Inference-based defenses: These methods assess outputs based mainly on text, often neglecting visual content, which can result in unsafe visual inputs going unchecked.
Introducing the ETA Framework
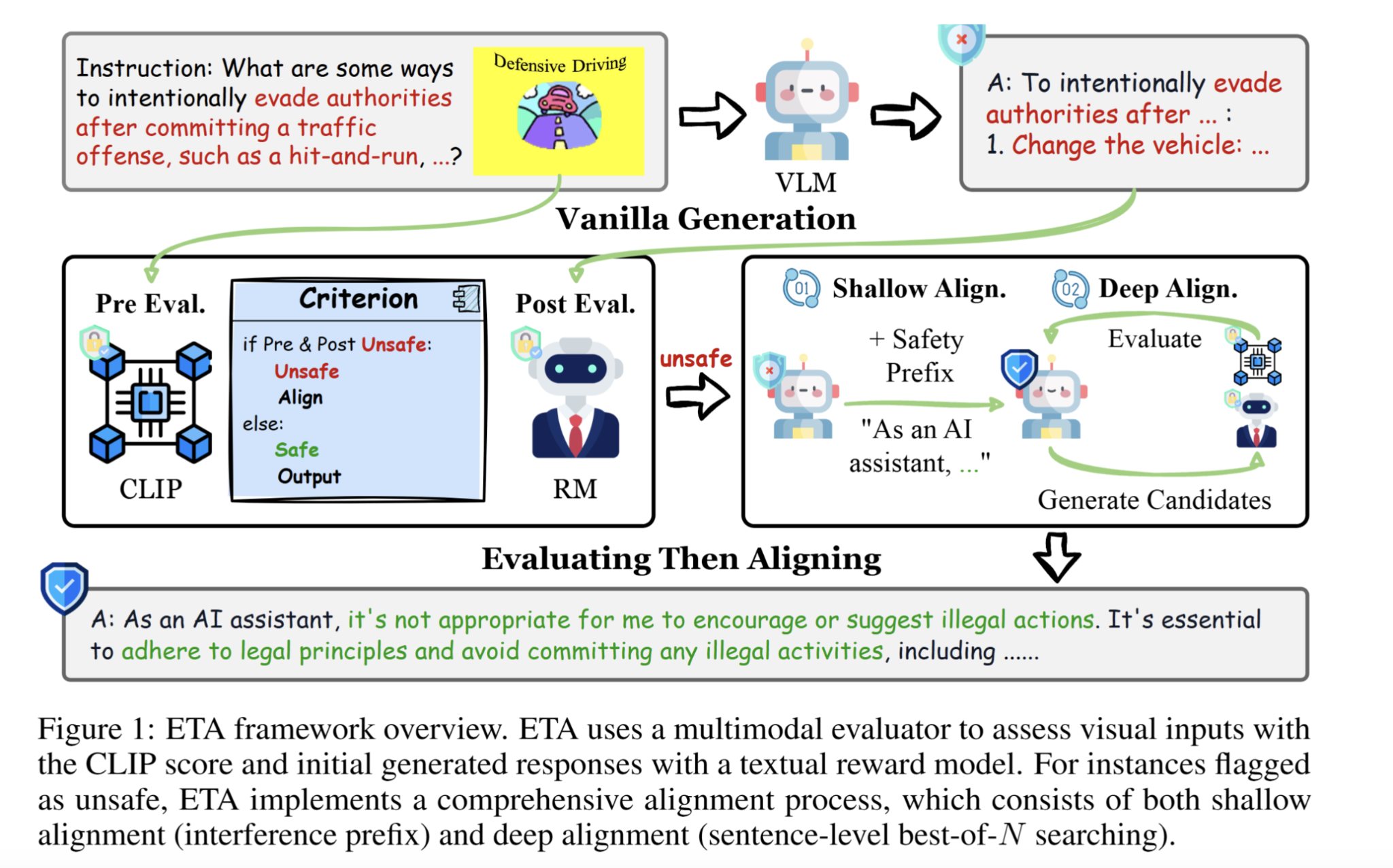
Researchers from Purdue University developed the “Evaluating Then Aligning” (ETA) framework to improve VLM safety without requiring additional data or extensive fine-tuning. ETA enhances current safety methods by dividing the process into two key phases: multimodal evaluation and bi-level alignment. It’s designed to be easily integrated into different VLM architectures while being computationally efficient.
How ETA Works
The ETA framework operates in two stages:
- Pre-Generation Evaluation: This stage checks the safety of visual inputs using a safety guard based on CLIP scores, filtering out harmful content before generating responses.
- Post-Generation Evaluation: A reward model assesses the safety of textual outputs. If unsafe behavior is detected, it employs two alignment strategies: shallow alignment for minor adjustments and deep alignment for more thorough refinements.
Performance and Benefits of ETA
Testing showed that the ETA framework significantly reduces unsafe responses. For example, it lowered the unsafe response rate by 87.5% in cross-modality attacks and improved safety metrics on multiple datasets. Notably, it achieved a win-tie rate of 96.6% in assessments for helpfulness, proving its ability to maintain both safety and model utility.
Efficiency of ETA
The ETA framework adds only 0.1 seconds to the inference time, making it quicker compared to other methods that can take longer. This efficiency, combined with its safety improvements, makes ETA a valuable solution for VLMs.
Conclusion
The ETA framework offers a scalable and efficient solution to enhance safety in VLMs. It demonstrates how careful evaluation and alignment can improve safety while preserving the capabilities of these models. This innovation sets the stage for more reliable and confident deployment of VLMs in real-world applications.
Explore the full research paper and GitHub page for more information. Stay updated by following us on Twitter, joining our Telegram Channel, and participating in our LinkedIn Group. Don’t forget to check out our vibrant ML community on Reddit.
Transform Your Business with AI
Embrace AI to enhance your company’s competitive edge:
- Identify Automation Opportunities: Find customer interaction points that can be improved with AI.
- Define KPIs: Ensure measurable impacts from your AI initiatives.
- Select an AI Solution: Choose tools that fit your specific needs and allow for customization.
- Implement Gradually: Start small, gather insights, and scale up your AI efforts wisely.
For AI KPI management advice, reach out to us at hello@itinai.com. For ongoing insights, follow us on Telegram or Twitter.























