
Understanding Multi-Hop Queries and Their Importance
Multi-hop queries challenge large language model (LLM) agents because they require multiple reasoning steps and data from various sources. These queries are essential for examining a model’s understanding, reasoning, and ability to use functions effectively. As new advanced models emerge frequently, testing their capabilities with complex multi-hop queries helps in truly assessing their performance and guiding them towards broader intelligence.
Existing Evaluation Methods Are Insufficient
Current methods for evaluating multi-hop reasoning are inadequate. They mostly rely on simulated queries which do not effectively verify the interconnection of tools or accurately assess multi-hop reasoning. This leads to inaccuracies and biases in model evaluations. Our focus is on a new method that reliably assesses a large language model’s ability to handle multi-hop queries.
Introducing ToolHop
ToolHop is a dataset created by researchers from Fudan University and ByteDance to evaluate multi-hop tools with 995 well-defined user queries and 3,912 related tools. ToolHop addresses the evaluation challenges by offering:
- Diverse queries
- Tools that can run locally
- Meaningful dependencies between tools
- In-depth feedback
- Answers that can be verified
Three Key Stages of ToolHop
The ToolHop process includes three main steps:
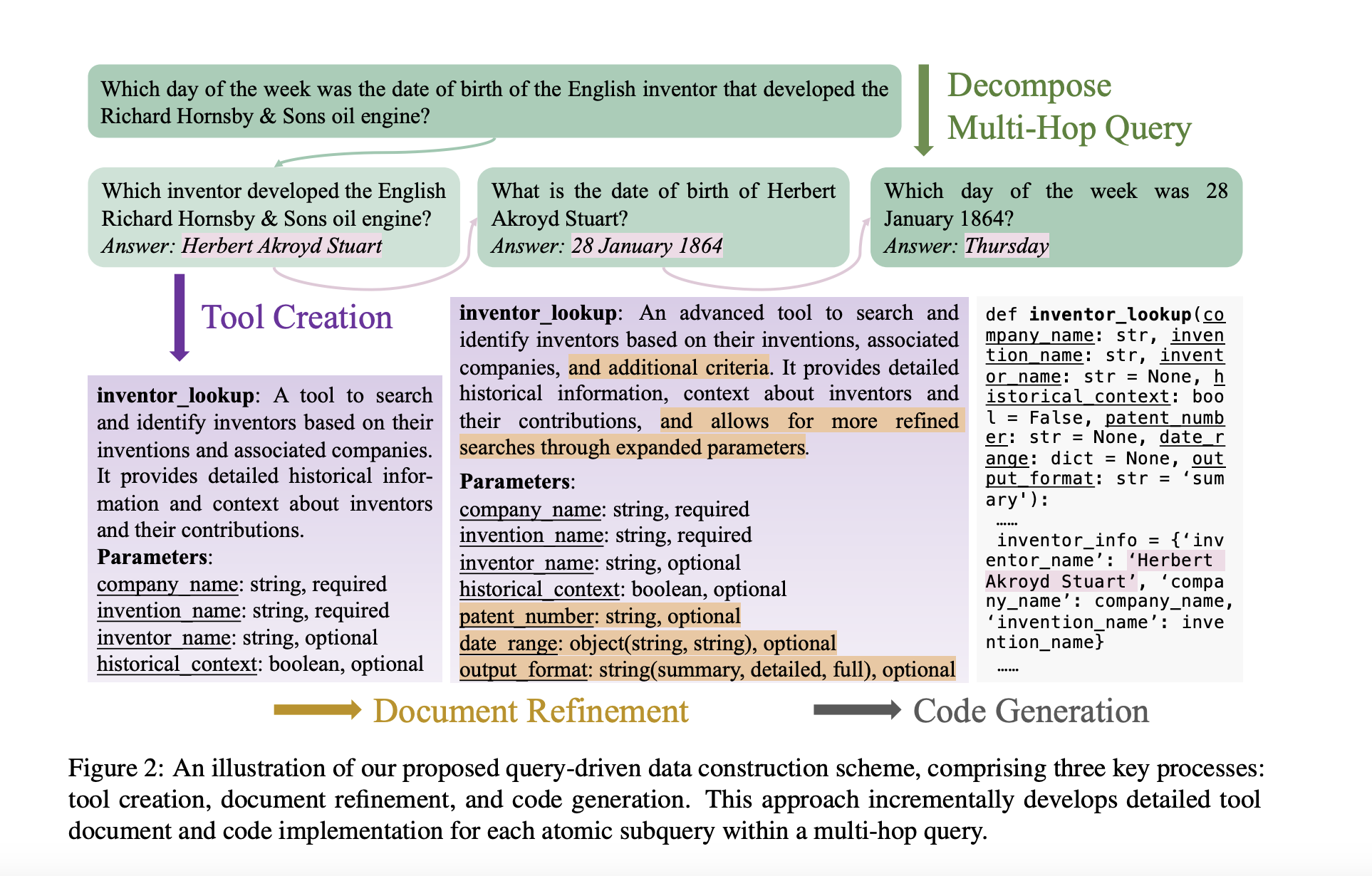
1. Tool Creation
A set of documents is generated based on user-provided multi-hop queries. These documents are organized into smaller, logical parts that can be understood and tackled individually, enhancing clarity and coherence.
2. Document Refinement
These documents are then filtered and improved to effectively evaluate models in complex scenarios. New features like result filtering are added, increasing the scope and usability of the tools.
3. Code Generation
Executable code is produced for the tools, allowing seamless interactions between the model and the tools during evaluations.
ToolHop’s Impact and Findings
ToolHop was evaluated using queries from the MoreHopQA dataset and tested on fourteen different LLMs. The evaluation addressed correctness and minimized errors. Findings showed that using tools improved model performance by up to 12% on average, and 23% for GPT models. The best model achieved a 49.04% accuracy rate, although it still generated incorrect answers around 10% of the time.
Conclusion
This research introduces a comprehensive dataset to tackle multi-hop queries effectively. The main takeaway is that while models have significantly improved with tool usage, there is still much room for enhancement in their multi-hop tool capabilities.
Get Involved!
Check out the full paper for more details. Stay connected with us on Twitter, Telegram, and LinkedIn. Join our growing community of over 60,000 ML enthusiasts on SubReddit.
Webinar Opportunity
Join our webinar for actionable insights into enhancing LLM performance and maintaining data privacy.
Unlock AI Potential for Your Business
To leverage AI effectively and remain competitive:
- Identify Automation Opportunities: Discover areas for AI to enhance customer interactions.
- Define KPIs: Ensure measurable impacts from your AI initiatives.
- Select an AI Solution: Choose tools that meet your needs and offer customization.
- Implement Gradually: Start with a pilot project, gather data, and expand wisely.
For advice on AI KPI management, please connect with us at hello@itinai.com. Stay updated on leveraging AI through Telegram at t.me/itinainews or on Twitter @itinaicom.
Discover how AI can transform your sales processes and enhance customer engagement. Explore our solutions at itinai.com.
























