Understanding Power Distribution Systems
Power distribution systems are often viewed as optimization models. While optimizing tasks for agents works well with few checkpoints, it becomes complicated when multiple tasks and agents are involved. As the scale increases, assignment problems become complex and often difficult to solve. Traditional optimization methods can be inefficient, consuming high resources and providing suboptimal results. These methods also require a dynamic, iterative approach. In AI, reinforcement learning (RL) is a promising solution for such state-dependent assignments.
Innovative Research from the University of Washington
Researchers from the University of Washington have developed a new multi-agent reinforcement learning method for satellite assignment problems. This approach effectively handles large-scale, realistic scenarios that would be overly complex for other methods. They introduced a well-designed algorithm that ensures specific rewards, meets global objectives, and avoids conflicts. By integrating existing greedy algorithms, they enhance long-term planning solutions.
Key Features of the New Methodology
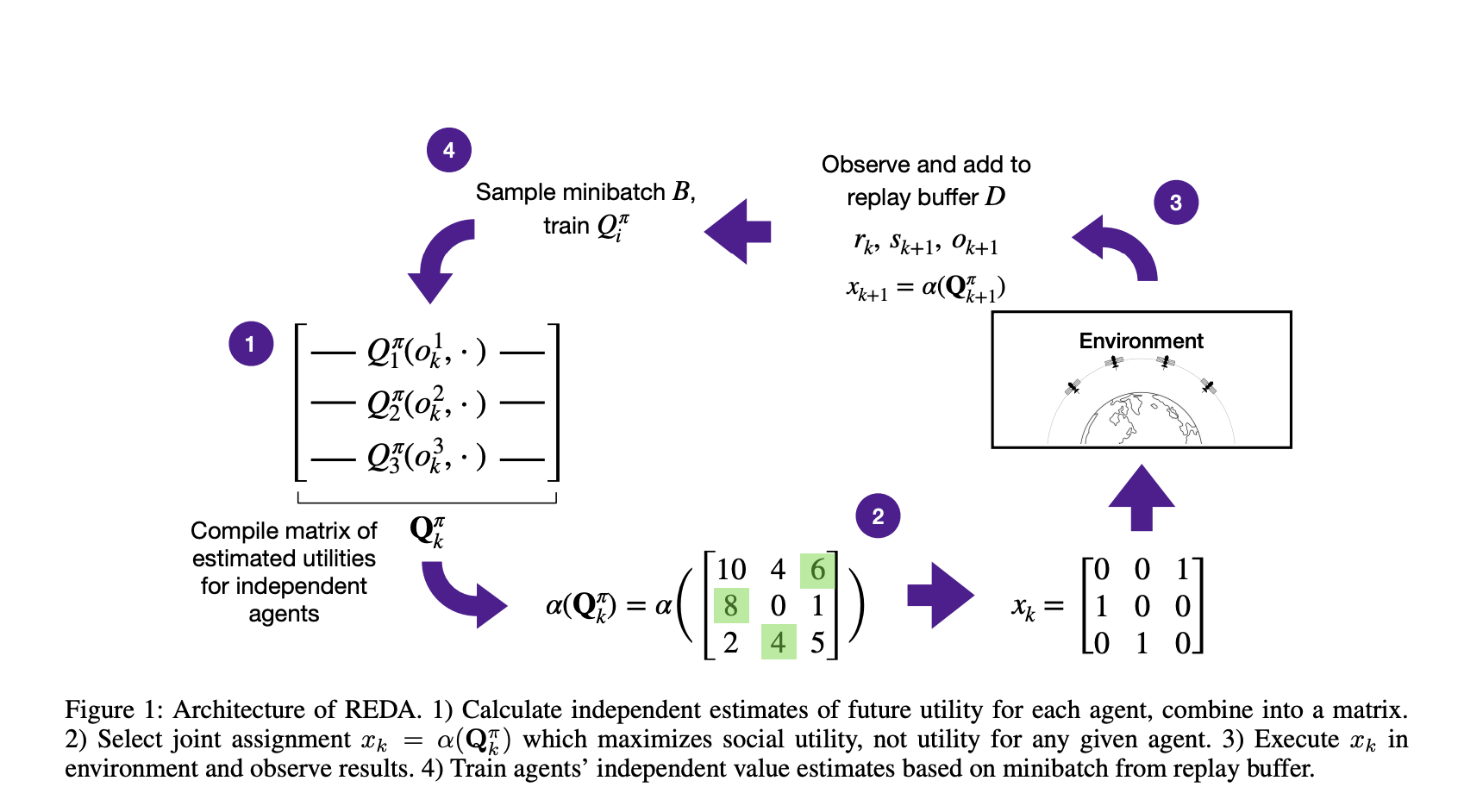
The unique aspect of this approach is that agents first learn an expected assignment value, which is then used for optimal task distribution. This enables agents to work together efficiently while learning a nearly optimal policy at the system level. The method focuses on satellite internet constellations, treating satellites as agents. The Satellite Assignment Problem is addressed using the RL-enabled Distributed Assignment algorithm (REDA). This algorithm starts with a non-parameterized greedy policy and incorporates random noise for exploration.
Evaluation and Results
The researchers conducted experiments in a simple environment and later scaled it to a complex satellite constellation with hundreds of satellites and tasks. They explored whether REDA promotes cooperative behavior and its effectiveness in large-scale problems. The results showed that REDA quickly led to an optimal joint policy, unlike other methods that encouraged selfish behavior. In complex scenarios, REDA consistently outperformed other methods, achieving a performance increase of 20% to 50%.
Conclusion
This research highlights REDA, a novel Multi-Agent Reinforcement Learning approach that effectively solves complex assignment problems, particularly in satellite assignments. It teaches agents to collaborate and find efficient solutions, even in large-scale settings.
Get Involved
Check out the Paper and GitHub Page for more details. Follow us on Twitter, join our Telegram Channel, and connect with our LinkedIn Group. Don’t forget to join our 60k+ ML SubReddit.
Join Our Webinar
Gain actionable insights into enhancing LLM model performance while ensuring data privacy.
Transform Your Business with AI
Stay competitive by leveraging REDA: A Novel AI Approach to Multi-Agent Reinforcement Learning. Discover how AI can transform your work processes:
- Identify Automation Opportunities: Find key customer interaction points that can benefit from AI.
- Define KPIs: Ensure measurable impacts on business outcomes from your AI initiatives.
- Select an AI Solution: Choose tools that fit your needs and allow for customization.
- Implement Gradually: Start with a pilot project, gather data, and expand AI usage wisely.
For AI KPI management advice, connect with us at hello@itinai.com. For ongoing insights into leveraging AI, follow us on Telegram t.me/itinainews or Twitter @itinaicom.
Explore how AI can enhance your sales processes and customer engagement at itinai.com.


























