
Introduction to CodeElo
Large language models (LLMs) have made great strides in AI, especially in code generation. However, assessing their true abilities is complicated. Current benchmarks like LiveCodeBench and USACO have shortcomings, such as:
- Inadequate private test cases
- Lack of specialized judgment systems
- Inconsistent execution environments
These issues make it hard to compare LLM performance with human coders. A standardized framework that reflects real-world programming challenges is necessary for accurate evaluation.
Introducing CodeElo
The Qwen research team has developed CodeElo, a benchmark to assess LLMs’ coding skills using human-like Elo ratings. CodeElo’s problems are sourced from CodeForces, a respected platform for programming contests. By submitting solutions directly to CodeForces, CodeElo ensures precise evaluations. It effectively addresses false positives and supports problems needing special judgment. The Elo rating system mirrors human performance, allowing for meaningful comparisons between LLMs and human coders.
Key Features and Benefits
CodeElo is built on three main components:
- Comprehensive Problem Selection: Problems are categorized by contest divisions, difficulty levels, and algorithmic tags for thorough assessment.
- Robust Evaluation Methods: Submissions are tested on the CodeForces platform, ensuring accurate judgments without hidden test cases.
- Standardized Rating Calculations: The Elo system evaluates correctness, considers problem difficulty, and penalizes errors, promoting high-quality solutions.
Results and Insights
Testing CodeElo on 30 open-source and three proprietary LLMs has provided valuable insights:
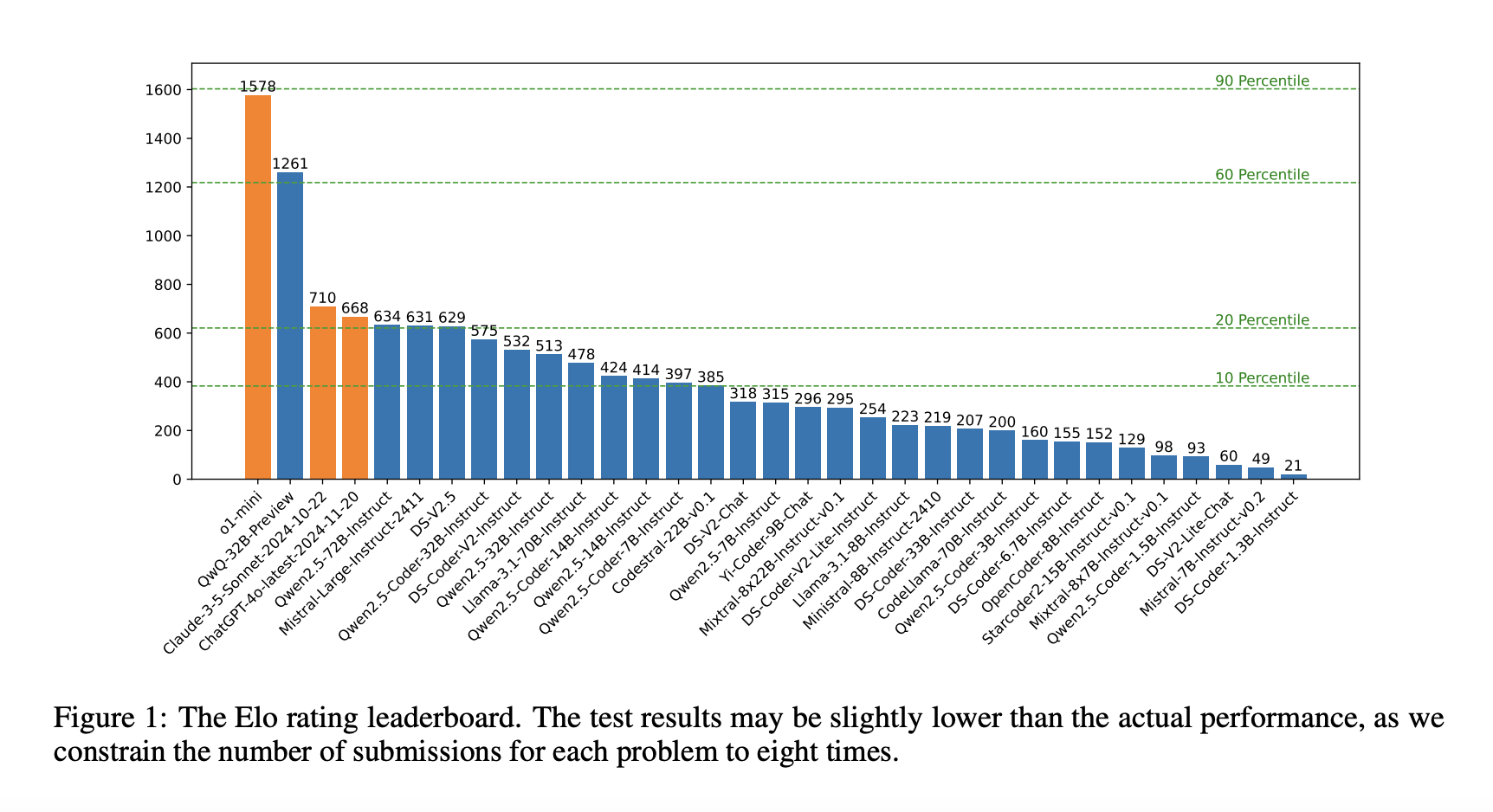
- OpenAI’s o1-mini model excelled with an Elo rating of 1578, outperforming 90% of human participants.
- Among open-source models, QwQ-32B-Preview led with a score of 1261.
- Many models struggled with simpler problems, often ranking in the bottom 20% compared to humans.
Models performed well in math and implementation but faced challenges with dynamic programming and tree algorithms. Additionally, they showed a preference for coding in C++, similar to competitive programmers. These findings highlight areas for improvement in LLMs.
Conclusion
CodeElo is a significant advancement in evaluating LLMs’ coding abilities. By overcoming the limitations of previous benchmarks, it offers a reliable framework for assessing competitive coding skills. The insights gained from CodeElo not only identify strengths and weaknesses but also inform future AI development in code generation. As AI evolves, benchmarks like CodeElo will be crucial for helping LLMs tackle real-world programming challenges effectively.
Get Involved
Check out the Paper, Dataset, and Leaderboard. All credit goes to the researchers behind this project. Follow us on Twitter, join our Telegram Channel, and connect with our LinkedIn Group. Don’t forget to join our 60k+ ML SubReddit.
Webinar Invitation
Join our webinar for actionable insights on enhancing LLM model performance and accuracy while protecting data privacy.
AI Solutions for Your Business
To stay competitive and leverage AI effectively, consider the following:
- Identify Automation Opportunities: Find key customer interactions that can benefit from AI.
- Define KPIs: Ensure measurable impacts on business outcomes.
- Select an AI Solution: Choose tools that fit your needs and allow for customization.
- Implement Gradually: Start with a pilot, gather data, and expand AI usage wisely.
For AI KPI management advice, contact us at hello@itinai.com. For ongoing insights into leveraging AI, follow us on Telegram or Twitter.
Transform Your Sales Processes
Discover how AI can redefine your sales and customer engagement processes at itinai.com.
























