
Understanding the Challenges of Large Language Models (LLMs)
Large Language Models (LLMs) have great potential, but they struggle to provide accurate responses based on the given information. This is especially important when dealing with long and complex documents in research, education, and industry.
Key Issues with LLMs
One major problem is that LLMs sometimes generate incorrect or “hallucinated” information. This means they can create text that sounds plausible but isn’t based on the actual input data. Such inaccuracies can lead to misinformation and a loss of trust in AI systems. To combat this, we need thorough benchmarks to evaluate how well LLMs stick to the facts.
Current Solutions and Their Limitations
Current methods to improve factual accuracy include:
- Supervised Fine-Tuning: Adjusting models to focus on factual content.
- Reinforcement Learning: Encouraging models to produce accurate outputs.
- Inference-Time Strategies: Using advanced prompting techniques to minimize errors.
However, these solutions can compromise other important qualities like creativity and diversity in responses. Therefore, a more effective framework is needed to enhance factual accuracy without losing these attributes.
Introducing the FACTS Grounding Leaderboard
To tackle these challenges, researchers from Google DeepMind and other organizations have created the FACTS Grounding Leaderboard. This benchmark measures how well LLMs generate responses based on extensive input contexts.
How It Works
The FACTS Grounding benchmark uses a two-step evaluation process:
- First, responses are checked for relevance. Ineligible responses are disqualified.
- Next, eligible responses are assessed for factual accuracy using multiple automated models, ensuring alignment with human judgment.
This rigorous evaluation helps prevent manipulation of the scoring system and ensures comprehensive responses that directly address user queries.
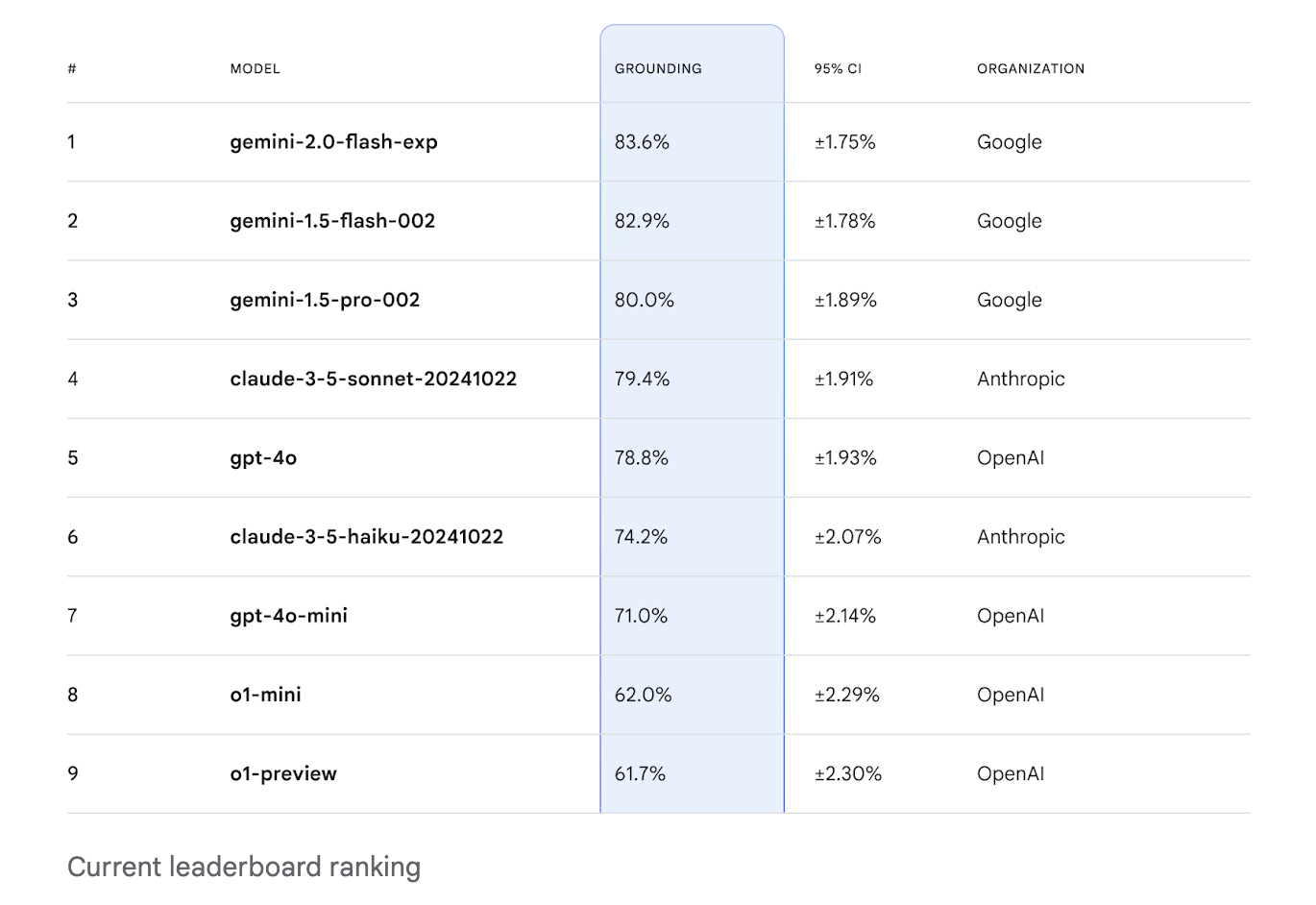
Performance Insights
The FACTS Grounding Leaderboard has shown varying performance among tested models:
- Gemini 1.5 Flash: 85.8% factuality on the public dataset.
- Gemini 1.5 Pro: 90.7% on the private dataset.
- GPT-4o: 83.6% on the public dataset.
These results highlight the benchmark’s effectiveness in distinguishing model performance and promoting transparency.
Why This Matters
The FACTS Grounding Leaderboard fills a crucial gap in evaluating LLMs, focusing on long-form responses rather than just short factuality or summarization. By maintaining high standards and continuously updating the leaderboard, it serves as a vital tool for improving LLM accuracy.
Next Steps for AI Development
If you’re looking to enhance your business with AI, consider these steps:
- Identify Automation Opportunities: Find customer interaction points that can benefit from AI.
- Define KPIs: Ensure your AI projects have measurable impacts.
- Select an AI Solution: Choose tools that fit your needs and allow customization.
- Implement Gradually: Start small, gather data, and expand wisely.
For more insights on leveraging AI, connect with us at hello@itinai.com or follow us on our social media platforms.

























