
Understanding the Importance of Visual Perception in LVLMs
Recent Advances
Large Vision Language Models (LVLMs) have made significant progress in multi-modal tasks that combine visual and textual information. However, they still face challenges, particularly in visual perception—the ability to interpret images accurately. This affects their performance in tasks that require detailed image understanding.
Current Evaluation Limitations
Many existing datasets, like MMMU and MathVista, do not focus on visual perception but rather on expert-level reasoning. This makes it difficult to evaluate how well LVLMs can perceive visual information. While general visual perception datasets target basic tasks such as counting or depth estimation, they often lack the detailed questioning needed for thorough assessment.
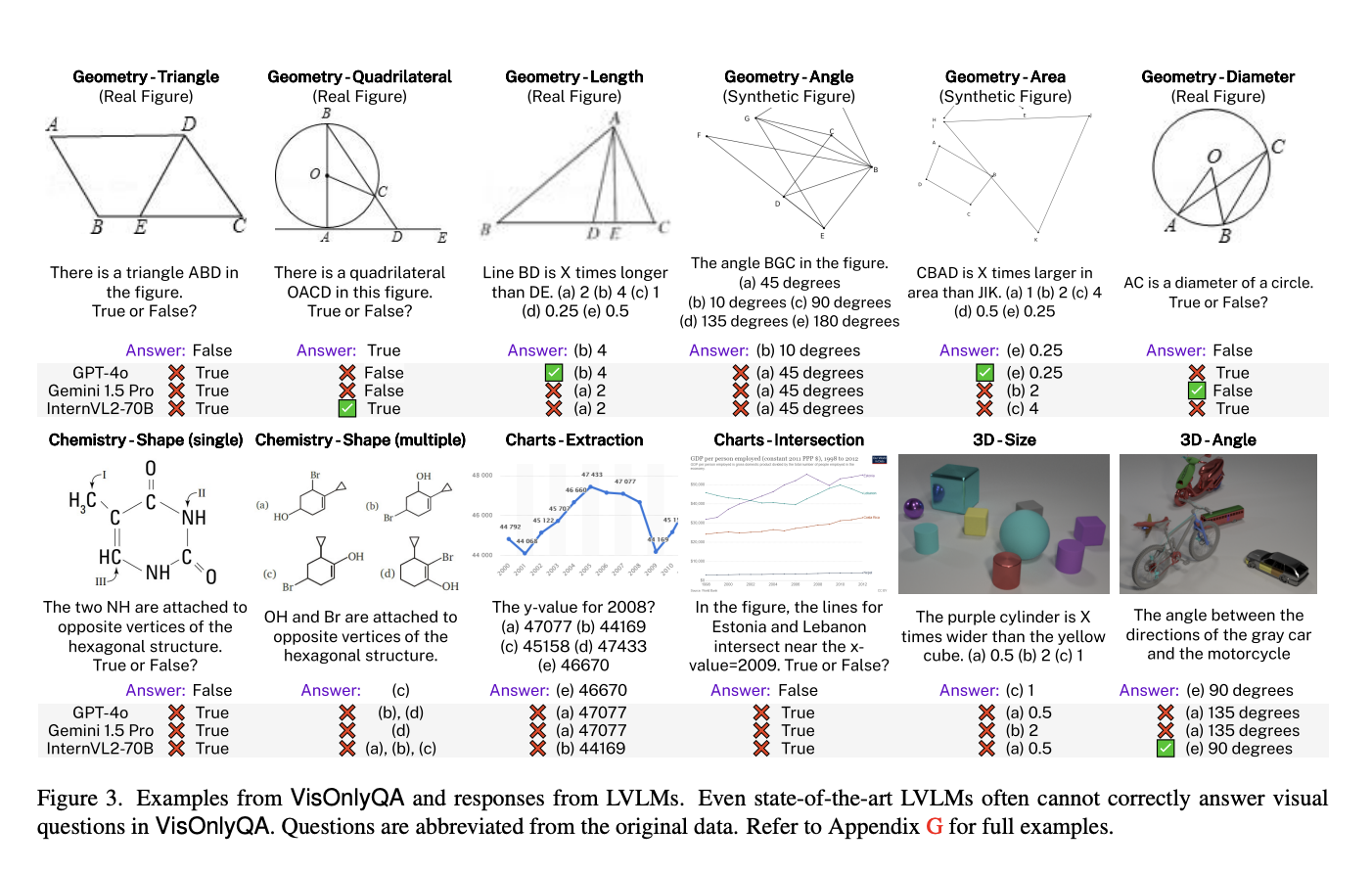
Introducing VisOnlyQA
To address these gaps, researchers from Penn State University created the VisOnlyQA dataset. This new resource is designed to evaluate LVLMs directly on geometric and numerical questions in scientific figures. VisOnlyQA emphasizes fine-grained visual details and uses synthetic figures to ensure diversity and precision. Questions are either manually annotated or automatically generated, eliminating the need for specialized knowledge.
Dataset Structure and Quality
The dataset comprises three sections: Eval-Real, Eval-Synthetic, and Train, all with balanced labels and high annotation quality, confirmed by human accuracy ranging from 93.5% to 95%.
Model Evaluation Results
The study tested 20 different LVLMs using the VisOnlyQA dataset, focusing on their performance in geometry, chemistry, and chart analysis. Results showed that these models generally performed worse than humans, with average accuracies of 54.2% for real-world data and 42.4% for synthetic data—well below human performance.
Current Challenges and Future Opportunities
Despite advancements in model sizes, many LVLMs struggled with visual perception tasks, suggesting a need for improvement. The research indicates that current methods, including chain-of-thought reasoning, do not consistently enhance performance on visual tasks. This highlights the necessity for better training data and model architectures.
Concluding Thoughts
VisOnlyQA serves as a valuable benchmark for assessing LVLMs’ visual perception abilities, revealing areas for improvement. This dataset opens new avenues for research and application in the field.
Boost Your Business with AI Solutions
To stay competitive, consider using VisOnlyQA and other AI tools. Here’s how you can leverage AI effectively:
1. Discover Automation Opportunities
Identify customer interaction points that can benefit from AI.
2. Define KPIs
Ensure that your AI initiatives have measurable impacts on your business.
3. Select the Right AI Solution
Choose tools that meet your specific needs and allow for customization.
4. Implement Gradually
Start with a pilot program, collect data, and expand your AI usage wisely.
Stay Connected
For AI KPI management advice, contact us at hello@itinai.com. For ongoing insights into leveraging AI, follow us on Telegram or Twitter @itinaicom.
Discover the potential of AI to redefine your sales processes and customer engagement at itinai.com.


























