Transforming AI with FastSwitch
Overview of Large Language Models (LLMs)
Large language models (LLMs) are revolutionizing AI applications, enabling tasks like language translation, virtual assistance, and code generation. These models require powerful hardware, especially GPUs with high-bandwidth memory, to function effectively. However, serving many users at once poses challenges in resource management and performance.
Resource Allocation Challenges
To provide quality service, it’s essential to allocate limited resources efficiently. This includes ensuring fairness among users and balancing response times. Traditional systems often focus on throughput but can ignore fairness, leading to delays and poor user experiences.
Issues with Current Solutions
Current solutions, like vLLM, use paging-based memory management to handle GPU memory limits. While they increase throughput, they still face issues like fragmented memory and low data transfer efficiency, particularly during multi-turn conversations. For example, the fixed block size in vLLM can lead to slower performance.
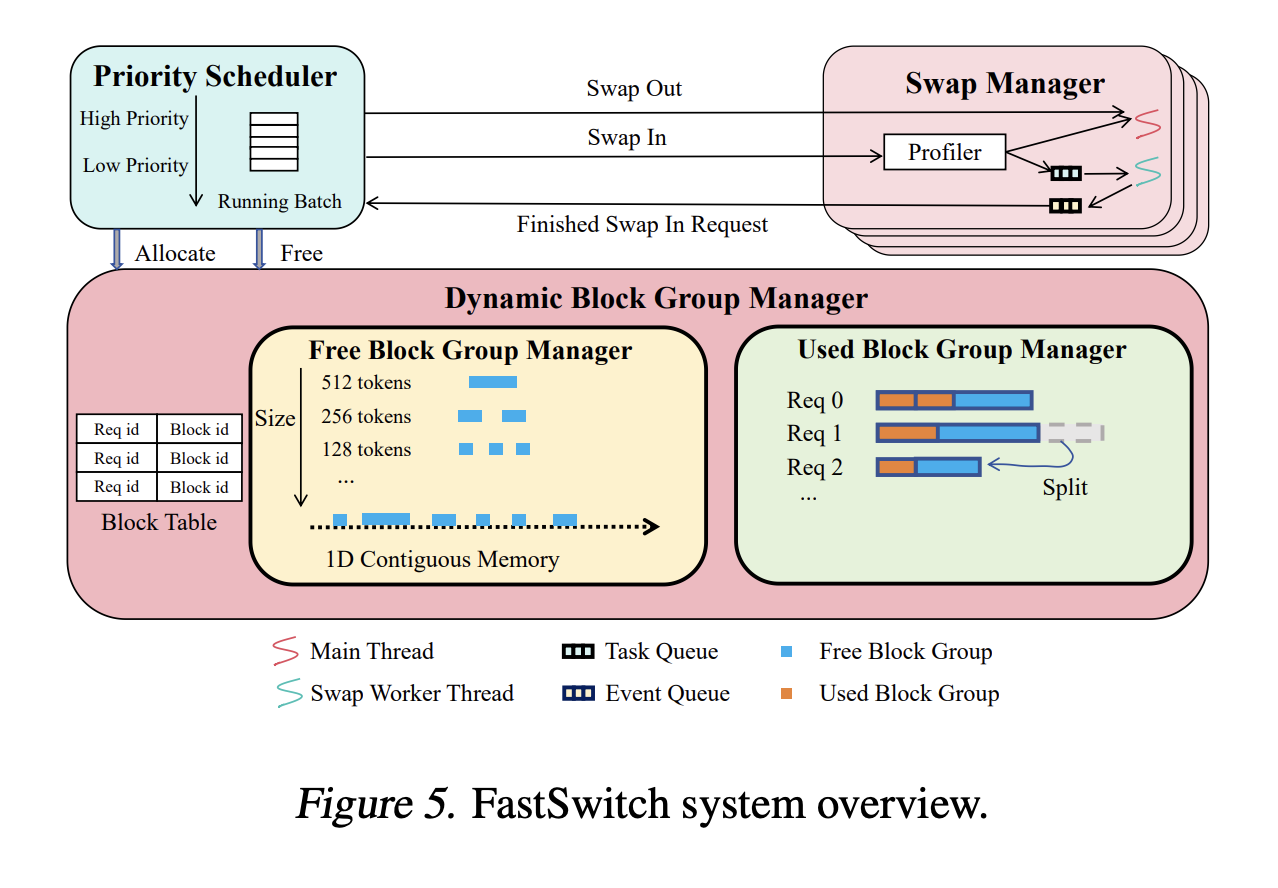
Introducing FastSwitch
Researchers from Purdue University and other institutions developed FastSwitch to improve LLM serving systems. FastSwitch focuses on three main optimizations:
– **Dynamic Block Group Manager:** This optimizes memory allocation, increasing transfer efficiency and reducing latency by up to 3.11 times.
– **Multithreading Swap Manager:** This allows for quicker token generation by enabling asynchronous memory swapping, reducing GPU idle time.
– **KV Cache Reuse Mechanism:** This minimizes unnecessary data transfers, cutting down preemption latency significantly.
Performance Improvements
FastSwitch has been tested with advanced models and GPUs, showing impressive results:
– **Speed Improvements:** Achieved speedups of 4.3-5.8 times in response times and improved throughput by up to 1.44 times.
– **Reduced Latency:** The KV cache reuse mechanism lowered swap-out blocks by 53%, enhancing efficiency.
– **Scalability:** Proven effective across multiple models, showcasing versatility for various applications.
Key Takeaways
– **Dynamic Block Group Manager:** Enhances I/O bandwidth and reduces context-switching latency significantly.
– **Multithreading Swap Manager:** Boosts token generation efficiency and minimizes idle GPU time.
– **KV Cache Reuse Mechanism:** Reduces data transfer volume and improves response times.
– **Overall Performance:** FastSwitch shows substantial improvements in handling high-demand workloads.
Conclusion
FastSwitch provides innovative solutions to improve fairness and efficiency in LLM serving. By reducing overhead and enhancing resource management, it ensures high-quality service for multiple users. This makes FastSwitch a game-changing solution for modern AI applications.
Get Involved
Check out the research paper for more details. Follow us on Twitter, join our Telegram Channel, or LinkedIn Group for insights. Subscribe to our newsletter and join our 55k+ ML SubReddit community.
Explore AI Solutions for Your Business
Elevate your company with AI by:
– **Identifying Automation Opportunities:** Find key areas for AI integration.
– **Defining KPIs:** Measure the impact of your AI initiatives.
– **Choosing the Right AI Solution:** Select tools tailored to your needs.
– **Implementing Gradually:** Start small, gather insights, and scale effectively.
For AI KPI management advice, reach out to us at hello@itinai.com. Stay updated with AI insights on our Telegram or Twitter. Discover how AI can transform your sales processes at itinai.com.


























