Advancements in Natural Language Processing (NLP)
Natural Language Processing (NLP) has made great strides thanks to deep learning, particularly through innovations like word embeddings and transformer architectures. A key method now is self-supervised learning, which uses large amounts of unlabeled data to train models, especially for languages like English and Chinese.
The Challenge of Low-Resource Languages
There is a significant gap in NLP resources between high-resource languages (like English and Chinese) and low-resource languages (like Portuguese). This gap limits the growth and effectiveness of NLP applications for low-resource languages, which often lack adequate models, benchmarks, and documentation.
Current Solutions for Portuguese NLP
Most Portuguese NLP development relies on multilingual models or fine-tuned English models, which often overlook the unique characteristics of Portuguese. Existing evaluation benchmarks are outdated or based on English datasets, making them less effective for Portuguese.
Introducing GigaVerbo and Tucano
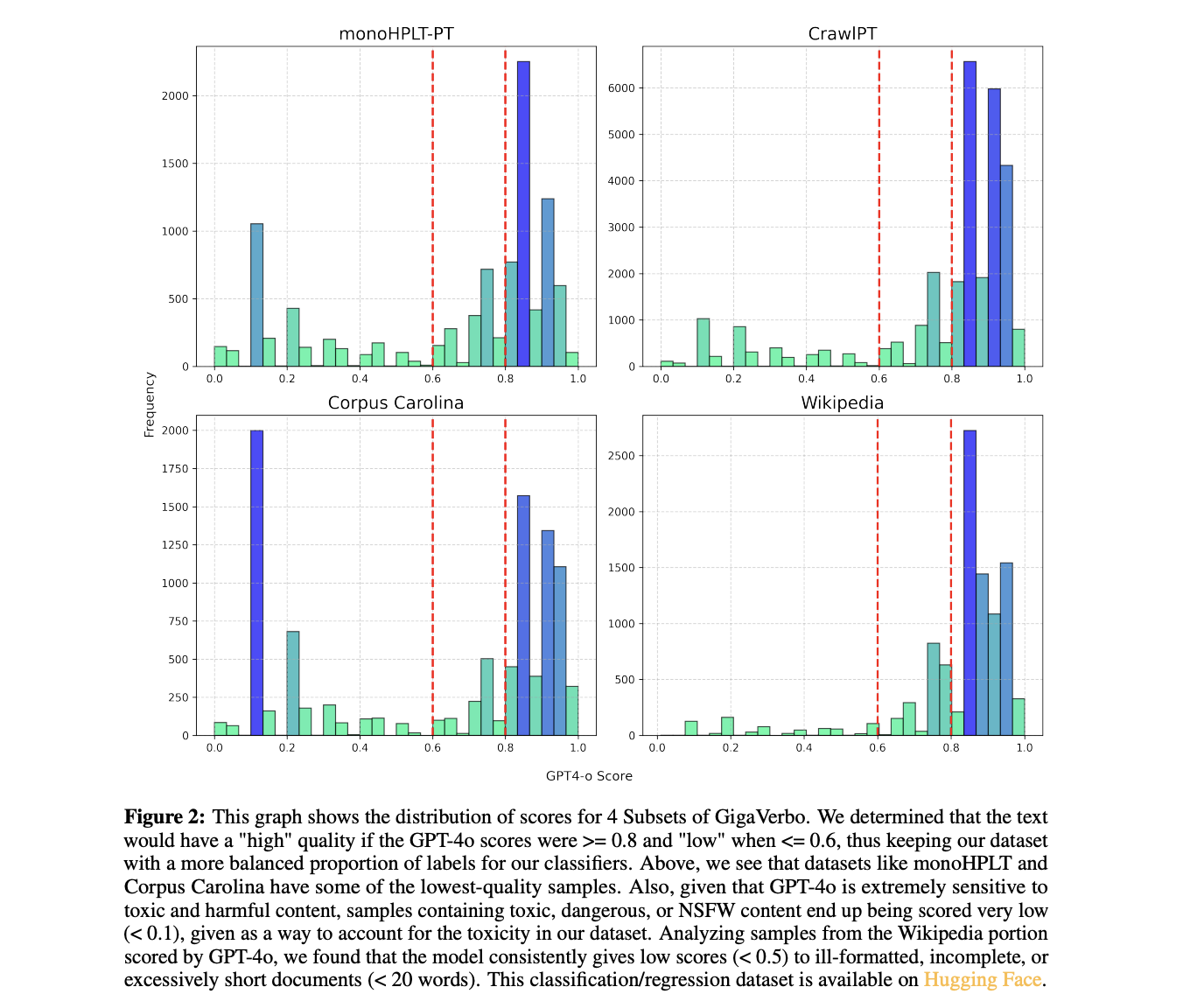
To tackle these challenges, researchers from the University of Bonn have created GigaVerbo, a large Portuguese text corpus with 200 billion tokens, and trained a series of models called Tucano. These models aim to enhance Portuguese language processing using a high-quality dataset.
Details of GigaVerbo and Tucano
The GigaVerbo dataset combines multiple high-quality Portuguese text sources, refined through custom filtering techniques. The Tucano models, based on the Llama architecture, are accessible via Hugging Face. They utilize advanced techniques like RoPE embeddings and root mean square normalization. The models range from 160 million to 2.4 billion parameters, trained on a massive amount of data.
Performance and Evaluation
The Tucano models have shown to perform as well or better than existing Portuguese and multilingual models on several benchmarks. The evaluation indicates that larger models generally achieve better results, and Tucano outperforms previous models in native evaluations.
Conclusion and Future Directions
The GigaVerbo dataset and Tucano models significantly improve Portuguese NLP capabilities. This work highlights the importance of large-scale data collection and advanced training techniques for low-resource languages. These resources will support future research and development.
Get Involved
Explore the Paper and Hugging Face Page. Follow us on Twitter, join our Telegram Channel, and connect on LinkedIn. If you appreciate our work, subscribe to our newsletter and join our 55k+ ML SubReddit.
Transform Your Business with AI
To stay competitive, leverage the Tucano models for your business. Here’s how:
- Identify Automation Opportunities: Find customer interaction points that can benefit from AI.
- Define KPIs: Ensure measurable impacts from your AI initiatives.
- Select an AI Solution: Choose tools that fit your needs and allow customization.
- Implement Gradually: Start with a pilot project, collect data, and expand wisely.
For AI KPI management advice, contact us at hello@itinai.com. Stay updated with AI insights on our Telegram or Twitter.
Explore AI for Sales and Customer Engagement
Discover more solutions at itinai.com.


























