
Challenges of Transformer-based Large Language Models (LLMs)
Transformer-based LLMs struggle with efficiently processing long sequences due to the complex self-attention mechanism, which leads to high computational and memory needs. This makes it difficult to use these models for tasks like multi-document summarization or detailed code analysis. Current methods can’t handle sequences of millions of tokens effectively, limiting their practical applications.
Current Solutions and Their Limitations
Several strategies have been proposed to enhance efficiency:
- Sparse Attention Mechanisms: These reduce computation but often lose critical global context, lowering performance.
- Memory Efficiency Techniques: Methods like key-value cache compression use fewer resources but sacrifice accuracy.
- Distributed Systems: Innovations like Ring Attention distribute tasks across devices but suffer from high communication overhead.
There is a clear need for a new method that balances efficiency, scalability, and performance without losing accuracy.
Introducing Star Attention
NVIDIA researchers have developed Star Attention, a block-sparse attention mechanism that efficiently processes long input sequences. Here’s how it works:
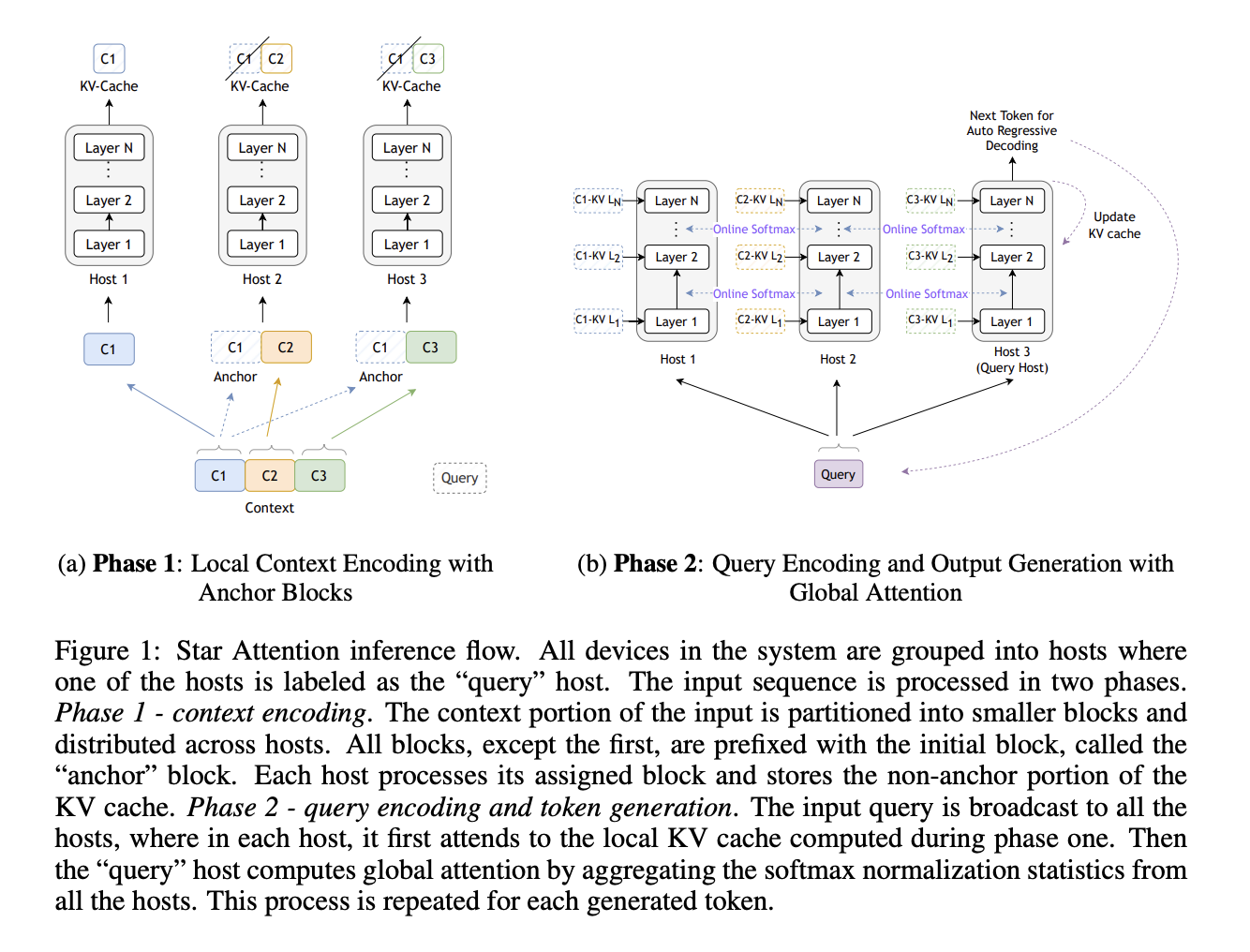
- The input sequence is divided into smaller blocks, starting with a crucial “anchor block” that maintains global information.
- Blocks are processed independently across multiple hosts, reducing computation complexity while capturing patterns effectively.
- A distributed softmax algorithm combines attention scores, enhancing global attention without heavy data transmission.
This model seamlessly integrates with existing Transformer frameworks, requiring no major adjustments for implementation.
How Star Attention Works
The process involves two main phases:
- Context Encoding: Each input block is paired with an anchor block to maintain global focus, and unnecessary cache data is eliminated to save memory.
- Query Encoding: Attention scores are calculated locally for each block and merged efficiently, maintaining speed and scalability.
Performance and Scalability
Star Attention has been evaluated on benchmarks like RULER and BABILong, handling sequences from 16,000 up to 1 million tokens. Using advanced hardware like HuggingFace Transformers and A100 GPUs, it demonstrates remarkable speed and accuracy:
- Achieves up to 11 times faster inference than standard models.
- Maintains 95-100% accuracy across various tasks.
- Only a minor accuracy drop (1-3%) in complex reasoning tasks.
It scales effectively, making it a versatile solution for applications requiring long sequences.
Conclusion and Future Directions
Star Attention represents a significant advance in efficiently processing long sequences in Transformer-based LLMs. Its innovative approach of using block-sparse attention and anchor blocks enhances both speed and accuracy, paving the way for broader applications in reasoning, retrieval, and summarization. Future work will focus on refining the anchor mechanisms and improving inter-block communication.
Get Involved
Explore more about this groundbreaking research in the Paper. Stay connected by following us on Twitter, joining our Telegram Channel, and our LinkedIn Group. If you appreciate our work, you’ll love our newsletter. Join our community of over 55k on our ML SubReddit.
Transform Your Business with AI
To stay competitive, leverage AI technologies effectively:
- Identify Automation Opportunities: Discover areas where AI can enhance customer interactions.
- Define KPIs: Set measurable goals for your AI projects.
- Select an AI Solution: Choose tools that fit your requirements and allow customization.
- Implement Gradually: Start small, gather insights, and expand wisely.
For more information, reach out at hello@itinai.com and stay updated via our Telegram or Twitter.
Discover how AI can transform your sales and customer engagement at itinai.com.


























