
Structured Generation and Its Importance
The rise of Large Language Models (LLMs) has made structured generation very important. These models can create human-like text and are now used to produce outputs in strict formats like JSON and SQL. This is crucial for applications such as code generation and robotic control. However, ensuring these outputs are structured correctly while maintaining speed is a challenge.
Challenges in Structured Output Generation
Despite improvements in LLMs, generating structured outputs can still be inefficient. A key issue is the high computational demand of following grammatical rules. Traditional methods require processing many possible tokens, leading to delays and increased resource use, making them unsuitable for real-time applications.
Current Solutions and Their Limitations
Current tools use constrained decoding to ensure outputs meet predefined rules. While this approach helps, it is often slow due to the need to evaluate each token against a stack of states. This complexity limits scalability, especially for larger vocabularies and intricate structures.
XGrammar: A New Solution
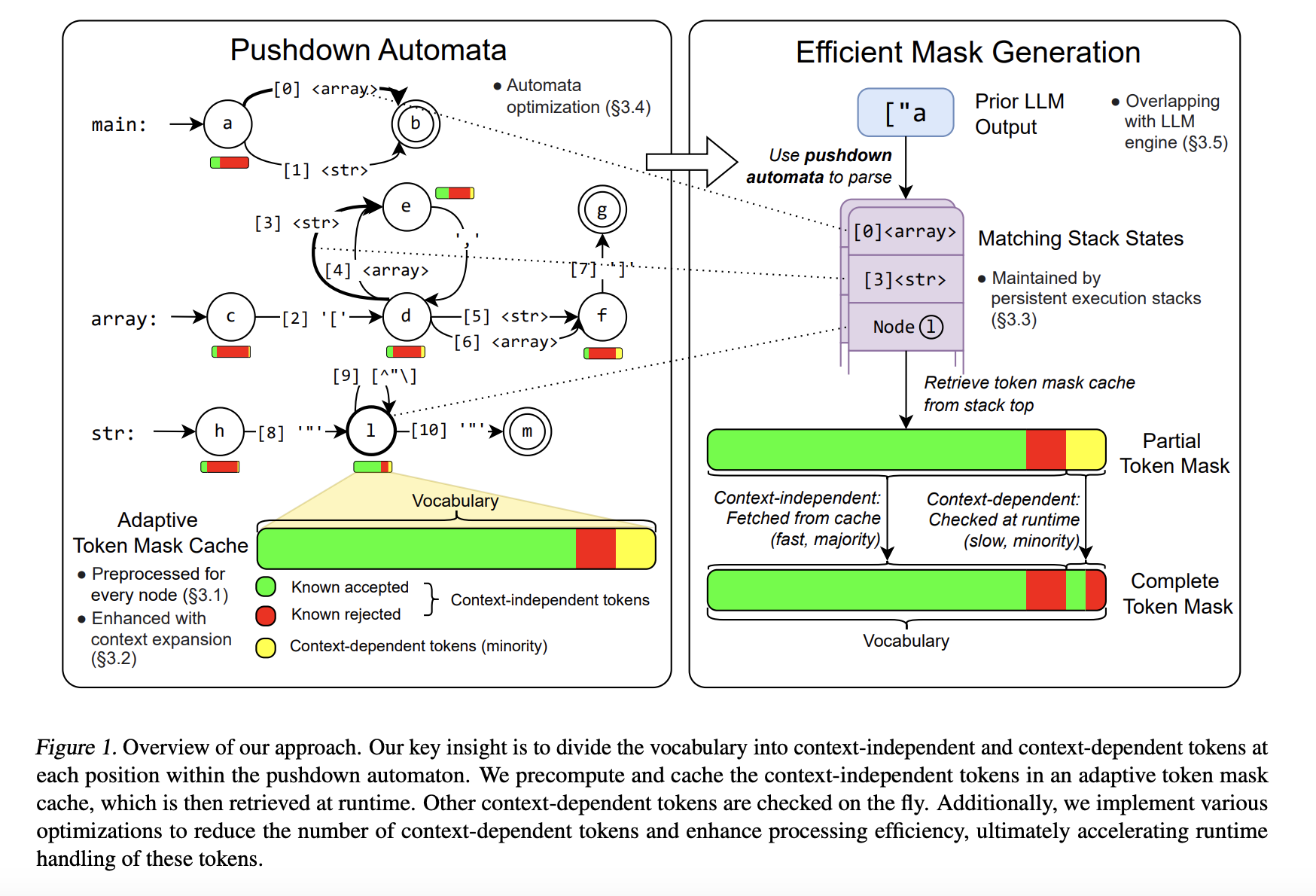
Researchers from several universities have developed XGrammar, a revolutionary structured generation engine. It categorizes tokens into two types: context-independent tokens that can be checked in advance, and context-dependent tokens that are evaluated during runtime. This method significantly reduces the computational load.
Key Innovations of XGrammar
- Efficient Processing: Uses a byte-level automaton for fast handling of complex grammar.
- Memory Optimization: The adaptive token mask cache cuts memory usage to just 0.2% of original requirements.
- Speed Improvements: Achieves a 100x speedup in generating structured outputs.
- Cross-Platform Use: Works on various platforms, including smartphones.
- Seamless Integration: Easily integrates with popular LLM models like Llama 3.1.
Performance and Impact
XGrammar shows impressive results, processing JSON grammar tasks in under 40 microseconds and improving structured output generation speed by 80x. Its memory efficiency allows it to handle large tasks effectively.
Key Takeaways
- Token Categorization: Reduces computational overhead significantly.
- Memory Efficiency: Scalable with minimal memory requirements.
- Enhanced Performance: Sets new benchmarks for processing speed.
- Cross-Platform Deployment: Versatile for different devices and environments.
- Integration with LLMs: Ensures easy adoption and compatibility.
Conclusion
XGrammar represents a significant advancement in structured generation for LLMs. By addressing inefficiencies and introducing innovative techniques, it provides a high-performance solution for generating structured outputs. With its impressive speed and reduced latency, XGrammar is essential for modern AI applications.
Get Involved
Check out the Paper and GitHub Page. Follow us on Twitter, join our Telegram Channel, and connect with us on LinkedIn. Subscribe to our newsletter for updates.
Join Our Free AI Virtual Conference
Don’t miss the SmallCon: Free Virtual GenAI Conference on Dec 11th. Learn from industry leaders about building with small models.
Transform Your Business with AI
To stay competitive, consider implementing XGrammar in your operations. Here are some steps to get started:
- Identify Automation Opportunities: Find areas in customer interactions that can benefit from AI.
- Define KPIs: Set measurable goals for your AI initiatives.
- Select an AI Solution: Choose tools that fit your needs and allow for customization.
- Implement Gradually: Start with pilot projects, collect data, and expand usage thoughtfully.
For AI KPI management advice, contact us at hello@itinai.com. For ongoing insights, follow us on Telegram or @itinaicom.
Discover how AI can enhance your sales processes and customer engagement at itinai.com.
























